1. 함수형 API_Wide_n_Deep
1) 데이터 불러오기 및 전처리
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 캘리포니아 주택 가격 데이터 셋 확인
Rawdict = fetch_california_housing()
Cal_DF = pd.DataFrame(Rawdict['data'], columns = Rawdict['feature_names'])
Cal_DF주요 포인트
- fetch_california_housing()
- 사이킷런에서 제공하는 캘리포니아 주택 가격 데이터셋을 가져옵니다.
- Rawdict라는 변수로 데이터를 받아옵니다.
- Rawdict['data']에는 입력 특징(Feature), Rawdict['target']에는 주택 가격 레이블(타겟)이 들어 있습니다.
- pd.DataFrame(...)
- 데이터를 판다스 데이터프레임 형태로 변환하여 컬럼 이름을 지정합니다.
이 셀에서는 데이터가 어떤 컬럼을 가지고 있는지와 전체적인 분포를 미리 확인해볼 수 있습니다.
Rawdict주요 포인트
- fetch_california_housing() 함수로 받아온 원본 데이터를 딕셔너리 형태로 확인할 수 있습니다.
- Rawdict.keys()를 통해 어떤 키들이 있는지 확인할 수도 있습니다.
Cal_DF.dtypes주요 포인트
- dtypes 를 통해 각 열의 데이터 타입을 확인합니다.
- 대부분 float64 형태로 되어 있을 것입니다.
Cal_DF.isnull().sum()주요 포인트
- 결측치(Null 값)가 존재하는지 확인합니다.
- 보통 0이 나오면 결측치 없이 데이터가 잘 구성되어 있음을 알 수 있습니다.
2) 데이터셋 분할
X_train_all, X_test, y_train_all, y_test = train_test_split(
Rawdict.data,
Rawdict.target,
test_size = 0.3
)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_all,
y_train_all,
test_size = 0.2
)
print("Train set shape : ", X_train.shape)
print("Validation set shape : ", X_valid.shape)
print("Test set shape : ", X_test.shape)주요 포인트
- train_test_split()
- 학습/검증/테스트 데이터 셋을 분할합니다.
- test_size=0.3로 먼저 train+valid : test = 7 : 3으로 나눕니다.
- 이후 train+valid 중 다시 test_size=0.2로 나누어서
최종적으로 train : valid : test = 0.56 : 0.14 : 0.3의 비율이 됩니다.
- 데이터 크기 확인
- X_train.shape, X_valid.shape, X_test.shape를 출력하여 분할이 잘 되었는지 확인합니다.
Rawdict['target_names']주요 포인트
- 캘리포니아 주택 가격의 타겟 이름을 확인합니다.
- 이 데이터셋에서는 ['MedHouseVal'](중간 주택 가격)의 의미를 가집니다.
3) 데이터 스케일 조정
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)주요 포인트
- StandardScaler
- 평균이 0, 분산이 1이 되도록 표준 정규화를 해주는 스케일러입니다.
- fit_transform(): 학습 데이터의 평균과 표준편차를 학습(fit)한 뒤, 학습 데이터에 대해 변환(transform)을 수행합니다.
- transform(): 이미 학습된(=fit 된) 평균·표준편차로 검증/테스트 데이터를 변환합니다.
- 주의 사항
- Train 데이터 기준으로 스케일링의 기준(평균, 분산)을 잡아야 과적합을 방지할 수 있습니다.
4) 모델 생성: 함수형 API(Functinal API)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import (Input, Dense, Concatenate)
X_train.shape
X_train.shape[1:]주요 포인트
- 텐서플로우(Keras)를 불러옵니다.
- X_train.shape: (샘플 수, 특성 개수) 형태로 되어 있으므로, X_train.shape[1:]를 통해 입력층에 필요한 특성 수(차원) 를 확인합니다.
# Model 생성하기
input = Input(shape=X_train.shape[1:]) # (특성 개수,) 형태를 입력으로 갖는 Input Layer
hidden1 = Dense(30, activation='relu')(input)
hidden2 = Dense(30, activation='relu')(hidden1)
# Wide & Deep에서 'Wide' 부분을 위해, 원래 Input도 최종 Output 층으로 합류
concat = Concatenate()([input, hidden2])
output = Dense(1)(concat)
model = keras.Model(inputs = [input], outputs = [output])
model.summary()
주요 포인트
- Input Layer
- shape=X_train.shape[1:] → 입력 데이터의 특성(feature) 개수만 지정합니다.
- batch 크기는 지정하지 않습니다(가변적).
- 은닉층(Hidden Layer)
- Dense(30, activation='relu')를 두 번 쌓아주어 심층 신경망(Deep part)을 형성합니다.
- Concatenate Layer (와이드 부분 추가)
- Concatenate()([input, hidden2])를 통해,
(Wide) 원본 입력 + (Deep) 은닉층의 출력 두 가지를 연결(concatenate)합니다. - 이렇게 하면, 단순 선형(입력 직결) + 심층 신경망을 동시에 학습하는 구조가 됩니다.
-

- Concatenate()([input, hidden2])를 통해,
- Output Layer
- 마지막에 Dense(1)(concat) 을 통해 최종적으로 1차원 스칼라(주택 가격)을 예측합니다.
- model = keras.Model(...)
- 함수형 API에서는 최종적으로 Model(inputs, outputs)로 실제 모델 객체를 생성해야 합니다.
- model.summary()를 통해 모델의 구조(층 개수, 파라미터 수)를 확인합니다.
tf.keras.utils.plot_model(model, show_shapes = True)주요 포인트
- plot_model
- 모델의 레이어 구조를 시각적으로 나타내 줍니다.
- show_shapes=True로 지정하면 각 레이어별 텐서의 형상(shape)도 함께 표시됩니다.
5) 모델 컴파일 및 학습
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
# 모델 컴파일
model.compile(optimizer = Adam(learning_rate = 0.005),
loss = 'msle', # 회귀 문제에서 MSLE 사용
metrics = ['accuracy']
)
# 조기 종료(early stopping) 콜백
early_stop = keras.callbacks.EarlyStopping(
monitor = 'val_loss',
patience=30,
restore_best_weights = True
)
# 모델 학습
history = model.fit(
X_train, y_train,
validation_data = (X_valid, y_valid),
epochs = 100,
batch_size = 32,
callbacks=[early_stop]
)주요 포인트
- model.compile(...)
- optimizer: Adam(학습률 0.005)
- loss: msle(Mean Squared Logarithmic Error)
- MSE에 로그를 적용한 형태로, 타겟 값이 큰 경우 발생하는 과도한 loss 폭 증가를 완화합니다.
- metrics: ['accuracy']
- 보통 회귀 문제에서는 accuracy를 쓰지 않지만, 예시로 설정한 것으로 보입니다. (RMSE나 MAE 등을 함께 볼 수도 있음)
- early_stop(조기 종료)
- 검증 손실(val_loss)이 증가하는 추세가 30 epoch 이상 지속되면 학습을 중단, 가장 성능이 좋았던 가중치로 복원해 줍니다.
- model.fit(...)
- validation_data를 함께 주어 검증 손실(val_loss)을 모니터링하게 합니다.
- epochs: 최대 100번 학습을 시도하되, early stopping으로 더 일찍 멈출 수 있습니다.
- batch_size: 한 번에 32개씩 가중치 업데이트를 진행합니다.
model.evaluate(X_test, y_test)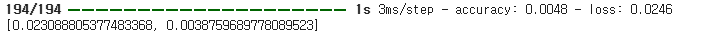
주요 포인트
- 학습이 끝난 모델을 테스트 데이터로 평가합니다.
- evaluate()는 (loss, metrics1, metrics2,...) 형태로 리턴합니다.
- 여기서는 loss(msle), accuracy를 리턴하게 됩니다.
6) 모델 학습 결과 시각화
def drawing_scalars(history_name):
history_DF = pd.DataFrame(history_name.history)
history_DF.plot(figsize=(12,8), linewidth=3)
plt.grid(True)
plt.legend(loc='upper right', fontsize=15)
plt.title("Learning Curve", fontsize=30, pad =30)
plt.xlabel('Epoch', fontsize=20, loc='center', labelpad=20)
plt.ylabel('Variables', fontsize=20, loc='center', labelpad=40)
# 테두리 제거
ax = plt.gca()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.show()
drawing_scalars(history)
주요 포인트
- history 객체
- model.fit() 결과로 반환되는 객체로, 학습 과정에서 epoch별로 기록된 손실값, 메트릭 값이 담겨 있습니다.
- history.history는 딕셔너리 형태입니다.
- 판다스 DataFrame으로 변환 후 시각화
- pd.DataFrame(history_name.history).plot(...) 를 통해
train과 val 곡선을 한 번에 시각화합니다.
- pd.DataFrame(history_name.history).plot(...) 를 통해
- 그래프 설정
- figsize, linewidth, grid(True), 레이블(xlabel, ylabel) 등을 통해 보기 좋게 그래프를 만듭니다.
7) 모델 예측 시연
X_train[0]
model.predict(X_train[0].reshape(1, 8))
주요 포인트
- model.predict(...)
- 모델이 실제 입력을 받아 예측값을 출력합니다.
- X_train[0].reshape(1, 8) 를 통해 샘플 하나만을 예측하는 예시입니다.
- reshape에서 (1, 8) 형태로 차원을 늘려주어 (배치 크기=1, 특성 수=8) 형태를 맞추어야 합니다.
정리
- Wide & Deep Learning:
- Wide 부분: 입력을 출력층에 직접 연결 → 선형 모델처럼 단순 규칙을 학습(암기)
- Deep 부분: 은닉층을 깊게 쌓아서 복잡한 패턴을 학습(일반화)
- 함수형 API의 핵심:
- 각 레이어를 함수처럼 불러와서 연결합니다.
- 모델을 만들 때, keras.Model(inputs, outputs)로 최종 선언합니다.
- MSLE 손실:
- MSE에 로그를 취해 타겟이 큰 경우에도 오류 폭발이 일어나지 않도록 완화합니다.
- EarlyStopping:
- 검증 데이터(val_loss)를 모니터링하여 성능이 좋아지지 않으면 학습을 자동으로 중단하고, 가장 좋은 가중치를 복원합니다.
이 코드를 통해, 캘리포니아 주택 가격 예측 문제에서 단순 선형 연결 + 심층 신경망 구조가 결합된 Wide & Deep 모델을 학습시킬 수 있습니다.
딥러닝 모델이 복잡한 패턴을 학습하는 동안, 와이드 부분이 비교적 단순한 규칙을 빠르게 학습하여 더 다양하고 예외적인 패턴까지 처리하는 것이 이 모델의 핵심 아이디어입니다.
2. 다중입력모델_Wide_n_Deep
개념 요약

- 다중 입력(Multi-Input) 모델
- Keras의 함수형 API를 이용하면 Input 레이어를 여러 개 둘 수 있습니다.
- 예) “간단한 규칙(Wide)”와 “복잡한 패턴(Deep)” 각각의 특징을 학습할 수 있도록, 특성을 구분해 입력합니다.
- Wide & Deep 모델
- Wide(Wide model): 입력을 출력층에 직접 연결하여 단순 선형(암기) 형태를 동시에 학습.
- Deep(Deep model): 은닉층을 거쳐 복잡한 패턴을 일반화하여 학습.
- 특성 분할(Feature Splitting)
- “상관관계가 뚜렷하거나 단순 패턴”처럼 보이는 컬럼 → Wide 쪽으로.
- “다소 복잡하거나 추가 분석이 필요한” 컬럼 → Deep 쪽으로.
- 어떤 컬럼은 동시에 Wide와 Deep에 넣어줄 수도 있음.
- 실험 예시
- (1) Deep에 4개, Wide에 5개 특성을 배분한 경우
- (2) Deep에 1개, Wide에 7개 특성을 배분한 경우
- (3) Deep과 Wide 모두 동일하게(모든 특성을 둘 다 주는 경우)
1) 다중 입력 Wide & Deep: 기본 예시
(1) 데이터 확인 및 전처리
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import callbacks
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Input, Dense, Concatenate, concatenate
# 1. 데이터 로드
Rawdict = fetch_california_housing()
California_DF = pd.DataFrame(Rawdict.data, columns=Rawdict.feature_names)
California_DF- fetch_california_housing(): 캘리포니아 주택 가격 데이터 로드.
- Rawdict: 특징, 타겟, 설명 등이 들어 있는 딕셔너리.
- California_DF: 각 독립변수(피처)를 담은 판다스 데이터프레임.


# 2. 데이터 컬럼 순서 재배치 (학습 실험 시 편의 위해)
California_DF = California_DF[[
"HouseAge", "Latitude", "Longitude", "MedInc",
"AveRooms", "AveBedrms", "Population", "AveOccup"
]]
# 3. 훈련/검증/테스트 세트 분할
X_train_all, X_test, y_train_all, y_test = train_test_split(
California_DF.values, Rawdict.target, test_size=0.3
)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_all, y_train_all, test_size=0.2
)
# 4. 스케일링(표준화)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid) # 주의: transform만!
X_test = scaler.transform(X_test)- Column 순서 재배치: 나중에 어떤 특성을 Deep에 넣고, 어떤 특성을 Wide에 넣을지 쉽게 제어하기 위함.
- train_test_split 두 번 호출로 (Train+Valid):Test = 7:3, 이후 Train:Valid = 8:2로 비율 조정.
- StandardScaler:
- fit_transform(): 학습용 데이터로 평균·표준편차 계산 → 변환
- transform(): 검증/테스트 데이터는 이미 계산된 평균·표준편차로 변환
(2) 입력층 분리 (Feature Split)
# 데이터를 input layer 2개에 나누어 넣기
# 예시: Deep에 앞 4개, Wide에 뒤 5개 (단, 중간에 'MedInc'가 겹침)
X_train_A, X_train_B = X_train[:, :4], X_train[:, 3:]
X_valid_A, X_valid_B = X_valid[:, :4], X_valid[:, 3:]
X_test_A, X_test_B = X_test[:, :4], X_test[:, 3:]
X_train_A.shape, X_train_B.shape- X_train_A: Deep Input (예: HouseAge, Latitude, Longitude, MedInc)
- X_train_B: Wide Input (예: MedInc(겹침), AveRooms, AveBedrms, Population, AveOccup)

※ 특성 중복: 예를 들어 MedInc를 Deep과 Wide 양쪽에 넣고 싶다면, 실제 슬라이싱으로 겹치는 부분이 일어나도록 분할합니다.
(3) 모델 구조 (함수형 API)
# 1) 입력층
input_A = Input(shape=[4], name='deep_input') # Deep쪽 (4개 특성)
input_B = Input(shape=[5], name='wide_input') # Wide쪽 (5개 특성)
# 2) Deep 부분
hidden1 = Dense(30, activation='relu', name='hidden1')(input_A)
hidden2 = Dense(30, activation='relu', name='hidden2')(hidden1)
# 3) Wide + Deep 합치기
concat = concatenate([input_B, hidden2], name='concat')
# 4) 출력층
output = Dense(1, name='output')(concat)
# 5) 모델 생성
model = keras.Model(inputs=[input_A, input_B], outputs=[output])
model.summary()- Input(): (배치 크기 제외) 각 입력층이 처리할 특성의 수를 지정.
- Dense(30, activation='relu'): 은닉층(Deep)
- concatenate(): “Wide”에 해당하는 입력값(input_B)와 “Deep” 은닉층 출력(hidden2)을 연결.
- 이렇게 이어 붙여 최종 출력층(Dense(1))으로 보냄 → Wide & Deep.
- 모델 요약(summar y): 레이어 구조와 파라미터 수를 확인.
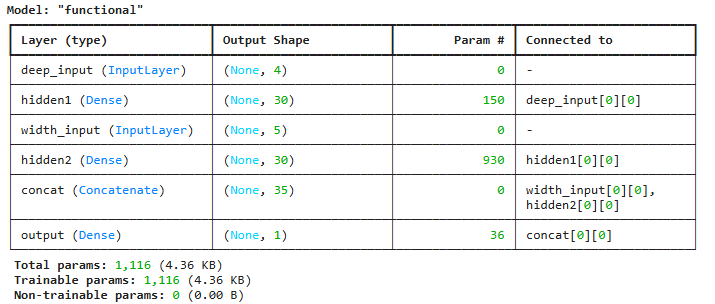
(4) 모델 학습 및 평가
model.compile(
optimizer=Adam(learning_rate=0.005),
loss='msle',
metrics=['accuracy'] # 회귀 모델에서는 일반적으로 RMSE, MAE 등을 사용; 여기서는 예시
)
early_stop = keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=30,
restore_best_weights=True
)
history = model.fit(
[X_train_A, X_train_B], # 두 개의 입력
y_train,
epochs=300,
validation_data=([X_valid_A, X_valid_B], y_valid),
callbacks=[early_stop]
)
model.evaluate([X_test_A, X_test_B], y_test)- model.compile(...): Adam optimizer, MSLE 손실 지정.
- early_stop: val_loss 모니터링, 30 epoch 동안 개선 없으면 학습 조기 종료 & 최적 가중치 복원.
- model.fit(...):
- 입력값을 [X_train_A, X_train_B] 형태의 리스트로 전달.
- 에포크 300번 시도(하지만 early stopping에 의해 더 일찍 멈출 수 있음).
-

- model.evaluate(...): 테스트 세트 성능 확인.

(5) 학습 곡선 시각화
def drawing_scalars(history_name):
history_df = pd.DataFrame(history_name.history)
history_df.plot(figsize=(12,8), linewidth=3)
plt.grid(True)
plt.legend(loc="upper right", fontsize=15)
plt.title("Learning Curve", fontsize=30, pad=30)
plt.xlabel('Epoch', fontsize=20, labelpad=40)
plt.ylabel('Variables', fontsize=20, rotation=0, labelpad=40)
ax = plt.gca()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.show()
drawing_scalars(history)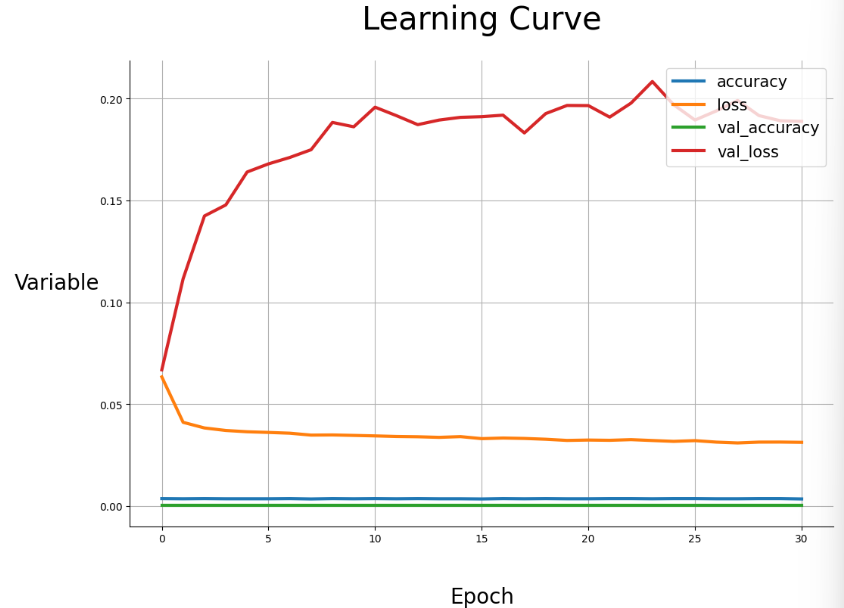
- history 객체(model.fit() 결과)를 판다스 DataFrame으로 변환 후, plot()으로 시각화.
- 학습 손실(loss), 검증 손실(val_loss)이 epoch에 따라 어떻게 변화하는지 확인.
2) 다중 입력 Wide & Deep: Deep에 1개 / Wide에 나머지
위 예시와 동일하지만, 이번에는 Deep에 1개 특성만 주고, 나머지 7개 특성을 Wide로 넣는 방식으로 구성해본 코드입니다.
# 1. 동일하게 순서 재배치
California_DF = California_DF[[
"HouseAge", "Latitude", "Longitude", "MedInc",
"AveRooms", "AveBedrms", "Population", "AveOccup"
]]
X_train_all, X_test, y_train_all, y_test = train_test_split(
California_DF.values, Rawdict.target, test_size=0.3
)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_all, y_train_all, test_size=0.2
)
# 2. 스케일링
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
# 3. Deep에는 첫 번째 컬럼만, Wide에는 나머지 7개 컬럼
X_train_A, X_train_B = X_train[:, :1], X_train[:, 1:]
X_valid_A, X_valid_B = X_valid[:, :1], X_valid[:, 1:]
X_test_A, X_test_B = X_test[:, :1], X_test[:, 1:]
# 4. 모델 생성
input_A = Input(shape=[1], name='deep_input')
input_B = Input(shape=[7], name='wide_input')
hidden1 = Dense(30, activation='relu')(input_A)
hidden2 = Dense(30, activation='relu')(hidden1)
concat = concatenate([input_B, hidden2])
output = Dense(1)(concat)
model = keras.Model(inputs=[input_A, input_B], outputs=[output])
model.summary()
# 5. 학습
model.compile(optimizer=Adam(learning_rate=0.005), loss='msle', metrics=['accuracy'])
early_stop = keras.callbacks.EarlyStopping(
monitor='val_loss', patience=30, restore_best_weights=True
)
history = model.fit(
[X_train_A, X_train_B], y_train,
epochs=300,
validation_data = ([X_valid_A, X_valid_B], y_valid),
callbacks=[early_stop]
)
model.evaluate([X_test_A, X_test_B], y_test)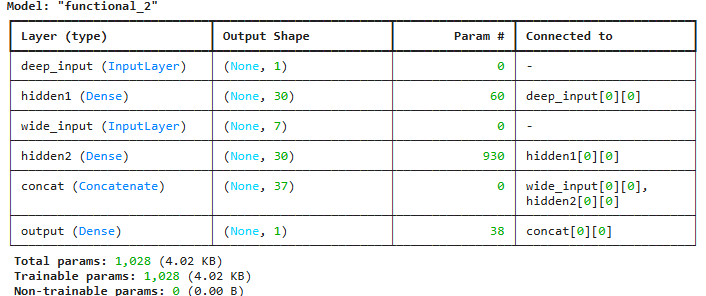
- Deep: 첫 번째 컬럼(예: HouseAge)만 → 복잡한 은닉층을 통과시키지만, 특성 자체가 1개이므로 모델이 큰 패턴을 잡아내기엔 제한적.
- Wide: 나머지 7개 컬럼 → 선형 연결로 간단한 규칙을 빠르게 학습.
- 실제로 성능 비교 시, “Deep 4개 vs. Wide 5개” 또는 “Deep 전체 vs. Wide 전체”처럼 분산해서 넣는 편이 더 나은 결과가 나올 수도 있습니다.


3) 결과 비교 예시
코멘트상 결과 예시:
- (1) 모든 특성을 Deep, Wide 동시에: loss: 0.0243
- (2) Deep 4개 / Wide 5개: loss: 0.0464
- (3) Deep 1개 / Wide 7개: loss: 0.0546
- 즉, Wide & Deep를 어떻게 나누어주느냐에 따라 성능 차이가 발생할 수 있음.
- 범주형(카테고리) 특성이 많은 대규모 데이터의 경우 Wide & Deep이 더 뚜렷한 이점을 보이기도 함.
4) 일반적인 다중 입력 모델의 활용

- CNN, RNN, Dense 등 서로 다른 방식의 특성 추출 모델로부터 나온 결과를 하나로 합치는 다중 입력도 가능.
- 예)
- 사용자 프로필 정보(Dense)
- 사용자 텍스트 리뷰(RNN)
- 사용자 업로드 이미지(CNN)
- → 모두 병합하여 최종 하나의 예측(추천, 분류, 회귀 등)
정리
- 다중 입력(Wide & Deep) 모델에서는
- Wide: 단순 규칙(암기) 역할
- Deep: 복잡한 패턴(일반화) 역할
- 특성(Feature)을 적절히 분리하여 각각의 입력층에 제공.
- 함수형 API를 이용하면
- Input()을 여러 개 사용 + concatenate()로 병합
- Keras Sequential로는 구현하기 까다로운 유연한 구조를 쉽게 만들 수 있음.
- 데이터 전처리 시 주의 사항
- 학습/검증/테스트 분할 먼저 → StandardScaler.fit_transform()은 학습용 데이터에만 적용(fit) → 나머지는 transform만!
- 실제 업무 적용
- 범주형(카테고리) 데이터가 많은 추천 시스템 등에서 Wide & Deep이 자주 쓰이며,
- 필요에 따라 CNN, RNN 등 다른 아키텍처를 동시에 활용하는 경우도 다중 입력 모델로 구현 가능.
위 예제 코드를 통해, "특성을 나누어 입력층을 여러 개 두는 방식"과, "Wide + Deep 구조를 함수형 API로 조합하는 방법"을 익힐 수 있습니다. 현업에서는 데이터 특성에 따라 어떤 컬럼을 Wide, Deep에 넣어야 할지 많은 실험과 도메인 지식을 활용해 최적 구성을 찾습니다.
'Programming > AI & ML' 카테고리의 다른 글
| [OUTTA Alpha팀 Medical AI& 3D Vision 스터디] 딥러닝 1(CNN 2) (0) | 2025.03.16 |
|---|---|
| [OUTTA Alpha팀 Medical AI& 3D Vision 스터디] 딥러닝 1(CNN 1) (0) | 2025.03.09 |
| [OUTTA Alpha팀 Medical AI& 3D Vision 스터디] 딥러닝 1(Keras 모델) (0) | 2025.02.15 |
| [OUTTA Alpha팀 Medical AI& 3D Vision 스터디] 딥러닝 1(신경망 구성요소 & 신경망 만들기) (0) | 2025.02.09 |
| [OUTTA Alpha팀 Medical AI& 3D Vision 스터디] 딥러닝 1(파이토치2) (0) | 2025.02.01 |