논문 링크: https://arxiv.org/pdf/1512.02325
OUTTA 논문 리뷰 링크: [2024-2] 조환희 YOLO, SSD
[2024-2] 조환희 YOLO, SSD
YOLO (You Only Look Once)R-CNN과 같은 Object dectection 방법은 이미지 안에서 obejct가 존재할만한 region을 추출해내는 과정(region proposal)을 수행한 후에, 추출된 region proposal에서 classification을 수행한다. regio
blog.outta.ai
1. YOLO (You Only Look Once)
1. 기존 방식(2 stage)와의 차이
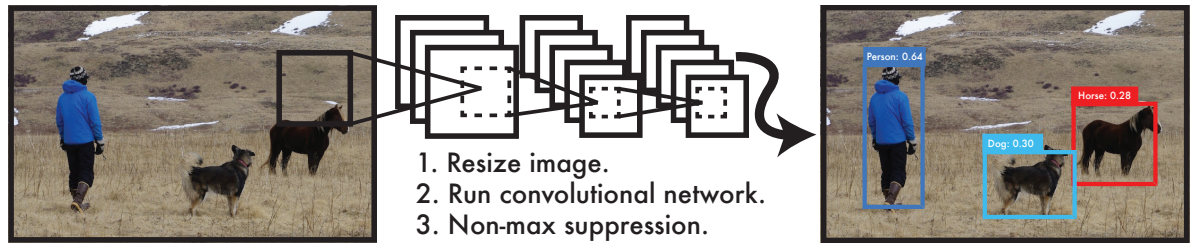
- R-CNN 계열: Region Proposal 생성 → Classification(2단계)
- 구조 복잡 → 연산량 많고 느림
- 각 단계 최적화도 별도로 진행 → 전체적으로 어렵
- YOLO: 1 stage로 Bounding Box와 Classification을 동시에 예측
2. 아이디어: Unified Detection
- 입력 이미지를 $S \times S$ 그리드로 나눔
- 각 Grid Cell마다 $B$개의 Bounding Box와 Confidence Score를 예측
- 동시에 Class Probability($P(\text{Class}|\text{Object})$)도 계산
- 최종적으로 Class-Specific Confidence: $$\text{Class-Specific Confidence} = P(\text{Class}|\text{Object}) \times \text{Confidence}$$ 로 구하여 물체 위치 + 클래스 얻음
3. Bounding Box 예측
- 각 Box는 $(x,\, y,\, w,\, h,\, \text{confidence})$로 구성
- $x,y$: Box 중심 좌표(그리드 셀 기준)
- $w, h$: Box의 폭과 높이
- $\text{confidence} = P(\text{Object}) \times \mathrm{IoU}(\text{Pred}, \text{GT})$
-

4. Network Architecture

- Convolution layer(24개)로 Feature 추출 후, Fully connected layer(2개)로 Box 좌표 + Class 확률 출력
- 학습 절차:
- 초기에 Conv Layer 20개 + 2 Layer 구성으로 ImageNet Classification Pre-training
- 이후 4 Conv + 2 FC를 추가 연결 → Object Detection 파트 학습
5. Loss Function & 개선
- 기본적으로 sum-squared error 사용:
- Localization Error + Classification Error
- 문제점
- Localization vs. Classification 간 동일 가중치 → 비효율
- 물체가 없는 Grid Cell이 많아 Confidence 예측 왜곡
- 작은 박스 vs 큰 박스 오차 처리 동일
- 해결책:
- Bounding Box 위치 오차(Localization)에 높은 가중치
- 물체가 없는 부분(Negative)에 대한 Confidence Loss는 가중치 감소
- $(w,h)$ 대신 $\sqrt{w}, \sqrt{h}$로 처리해 큰/작은 박스 차이를 줄임

6. 한계
- Grid Cell마다 B개의 Box 제한 → 가까이 붙어 있는 물체 탐지 어려움
- Bounding Box Ratio가 학습 데이터와 많이 다르면 일반화 어려움
7. 요약
- 장점:
- 구조 간단, End-to-End, 빠른 속도
- 전체 이미지를 한꺼번에 보고 학습 → 도메인 전이(Generalization)에 강점
- 단점:
- 작은 객체, 밀집된 객체 탐지에는 한계
2. SSD (Single Shot Detector)
1. 목표
- 2 Stage Detector(Faster R-CNN 등)의 정확도 + 1 Stage Detector(YOLO 등)의 속도를 모두 확보
2. Network Architecture

- Base Network:
- VGG16 기반으로, FC Layer를 Conv Layer로 대체 → 연산 효율 향상
- Auxiliary Network:
- VGG16 후단에 추가로 Conv Layers를 더 쌓아, 다양한 크기(Multi-scale) Feature Map 생성
- 각 Scale마다 Bounding Box 예측에 사용
3. Multi-scale Feature Maps

- YOLO는 단일 7×7 Feature Map만 사용 → 다양한 크기 물체 처리 어려움
- SSD는 여러 단계의 Feature Map(예: 38×38, 19×19, 10×10, …)에서 각각 객체 탐지 수행
- 작은 Map → 큰 물체
- 큰 Map → 작은 물체
4. Default Boxes & Aspect Ratios

- 각 Feature Map cell마다 여러 Default Box(scale, ratio 다름)를 정의
- $\text{Scale} = s_k,\quad k \in \{ \dots \}$
- Predictor가 각 Default Box에 대해 $(c+4)\cdot k$개의 출력을 계산
- $c$: 클래스 수, 4: Box 오프셋($x,y,w,h$), $k$: Default Box 개수
- 이렇게 하면 다양한 박스 비율/크기를 한 번에 처리 가능
5. Training
1. Matching
- Default Box와 Ground Truth Box 간 IoU 확인
- IoU > 0.5 (또는 전체 중 최고 IoU) → 해당 Default Box와 매칭
2. Loss Function
- 총 Loss = Localization Loss + Confidence Loss (가중치 $\alpha=1$)
- $$\mathrm{Loss} = \frac{1}{N} \Bigl( L_{\text{conf}} + \alpha \,L_{\text{loc}}\Bigr)$$
- NN: 매칭된 Default Box 수, 없으면 0
- Localization Loss:
- Smooth L1로 Box 좌표($c_x,c_y,w,h$) 회귀
- Confidence Loss:
- 각 Box의 Class Score에 대한 Softmax Loss
6. 결과 및 요약
- Fast: 전체 Network가 분리되지 않고 End-to-End 구조
- Accurate: Multi-scale Feature Maps + 다양한 Default Box로 크기 다른 객체 잘 탐지
- 예시 결과 (PASCAL VOC):
- Faster R-CNN: 7 FPS, mAP=73.2%
- YOLO v1: 45 FPS, mAP=63.4%
- SSD: 59 FPS, mAP=74.3% (속도+정확도 모두 우수)
정리
- YOLO:
- 간단하고 빠른 One-stage Detector
- Bounding Box와 Class 예측을 동시에 수행
- 작은 객체/밀집 객체에 약점
- SSD:
- 멀티 스케일 Feature Map + Default Box → 다양한 크기 객체 포착
- VGG16 + Auxiliary Conv 구조
- 빠른 속도 + 높은 정확도를 동시에 달성