논문 링크: 2010.11929
OUTTA 논문 리뷰 링크: [2024-2] 전윤경-An image is worth 16X16 Words : transformers for image recognition at scale
[2024-2] 전윤경-An image is worth 16X16 Words : transformers for image recognition at scale
0. AbstractTransformer 아키텍처를 이미지 패치 시퀀스에 적용한 Vision Transformer(ViT)는 CNN 없이도 이미지 분류 작업에서 뛰어난 성능을 발휘한다. ViT는 대규모 데이터로 사전 학습 후 전이 학습 시, 최
blog.outta.ai
1. Introduction
- Transformer 구조는 NLP에서 성공적으로 활용됨.
- 높은 연산 효율성과 확장성이 특징.
- 데이터셋과 모델 크기가 커져도 성능이 포화되지 않고 지속적으로 개선.
- Computer Vision Task에서 Transformer 구조 적용의 어려움:
- Self-Attention은 $O(n^2)$ 복잡도로 계산 비용이 높음.
- CNN 기반 모델과의 하드웨어 가속기 호환성이 부족.
- Vision Transformer (ViT):
- 이미지를 패치 단위로 분할하여 Transformer 입력으로 사용.
- Inductive Bias가 부족하지만, 대규모 데이터셋에서 사전학습을 통해 극복.
- ImageNet-21k 및 JFT-300M에서 사전학습 후 다양한 다운스트림 데이터셋에서 우수한 성능 달성.
2. Related Work
- NLP:
- Vaswani et al. (2017): Transformer 구조 제안.
- Devlin et al. (2019): BERT로 Self-Supervised Pretraining 도입.
- GPT 시리즈: 언어 모델링 기반 사전학습 수행.
- Computer Vision:
- Self-Attention을 CNN에 적용하거나 대체하려는 다양한 시도.
- Cordonnier et al. (2020): 2x2 패치로 Self-Attention 적용 (ViT와 유사).
- Image GPT (Chen et al., 2020): Transformer를 이미지 픽셀 단위에 적용.
- ViT의 차별점:
- 대규모 데이터셋(ImageNet-21k, JFT-300M)을 활용한 학습.
- 기존 CNN 기반 ResNet보다 더 좋은 성능 달성.
3. Methodology
3.1 Architecture

Patch Embedding:

- 이미지를 크기 $(P, P)$ 패치로 분할: $$N = \frac{H \cdot W}{P^2}$$
- $H, W$: 입력 이미지 크기.
- $P$: 패치 크기.
- 각 패치를 1D 벡터로 변환하고, Linear Projection을 통해 고정 차원 $D$로 변환.
Positional Embedding:
- 각 패치에 위치 정보를 추가하여 순서 학습 가능.
- 패치 임베딩 벡터에 위치 임베딩 벡터를 더함.
Transformer Encoder:
- Multi-Head Self-Attention (MSA)와 MLP Block으로 구성.
- Layer Normalization과 Residual Connection 적용.
Classification Head:

- 패치 임베딩 앞에 CLS 토큰 추가 → 이미지 전체 표현.
- 최종 출력 $\text{CLS} 토큰을 사용해 Linear Layer로 분류 수행.
3.2 Attention
- Self-Attention:
- 입력 $z$를 $Q, K, V$로 변환: $$\quad W^{QKV} \in \mathbb{R}^{D \times 3D}
- Attention 가중치 계산: $$A = \text{softmax}\left(\frac{QK^T}{\sqrt{D_h}}\right)$$
- $D_h = \frac{D}{k}$, $k$: Attention Head 개수.
- Multi-Head Self-Attention (MSA):
- 여러 개의 Self-Attention Head 출력 병합: $$MSA(z) = \text{Concat}(SA_1(z), \dots, SA_k(z)) W^{MSA}, \quad W^{MSA} \in \mathbb{R}^{kD_h \times D}$$
- Feedforward Network (FFN):
- 두 개의 Fully Connected Layer: $$FFN(x) = \text{ReLU}(x W_1 + b_1)W_2 + b_2$$
- $W_1 \in \mathbb{R}^{D \times D_{hidden}}, W_2 \in \mathbb{R}^{D_{hidden} \times D}$
- 두 개의 Fully Connected Layer: $$FFN(x) = \text{ReLU}(x W_1 + b_1)W_2 + b_2$$
3.3 Inductive Bias
- CNN과 Inductive Bias
- CNN은 이미지에 특화된 다음과 같은 Inductive Bias를 가짐:
- Locality: 근접 픽셀 간의 종속성을 활용.
- Translation Equivariance: 입력 변화에 따라 출력이 동일하게 변화.
- ViT는 이러한 Inductive Bias가 약함.

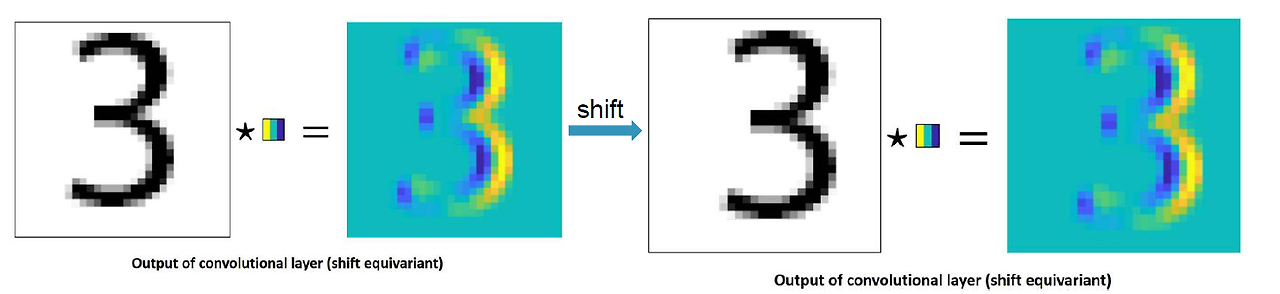
Locality / Translation Equivariance
- CNN은 이미지에 특화된 다음과 같은 Inductive Bias를 가짐:
- ViT의 Inductive Bias 보완
- Data-Driven Training:
- 대규모 데이터셋에서 학습하여 Inductive Bias 부족을 극복.
- Positional Embedding:
- 패치 간의 관계를 학습하여 Locality와 Translation Equivariance 간접 학습.
- Hybrid Architecture:
- CNN으로 Feature Map을 추출하여 Transformer에 입력으로 사용 → Locality와 Translation Equivariance 활용.
- Data-Driven Training:
- Fine-Tuning with Higher Resolution
- 사전학습된 모델을 더 높은 해상도에서 Fine-Tuning 시 성능 향상.
- 기존 Positional Embedding은 해상도 변화로 왜곡될 수 있음.
- 2D Interpolation:
- Positional Embedding을 보간하여 새로운 해상도에 맞춤.
- 이를 통해 ViT 내부에 이미지에 특화된 Inductive Bias를 추가적으로 포함.

4. Inspecting Vision Transformer (ViT의 내부 분석)
ViT의 내부 작동을 분석하기 위해 3가지 실험을 수행:
4.1. 필터 시각화 (Filter Visualization)

- 목적: Linear Projection 레이어가 학습한 Low-Level Feature를 이해.
- 방법:
- 첫 번째 Linear Projection의 주요 요소 28개를 선정하여 시각화 (PCA로 차원 축소한 것으로 추정).
- 기존 가중치 행렬을 변환 후 시각화.
- 결과:
- CNN 초기 레이어에서 나타나는 Edge, Color 등 Low-Level Feature와 유사한 패턴.
- ViT도 CNN처럼 Low-Level Feature를 효과적으로 학습.
4.2. 위치 임베딩 유사도 분석 (Positional Embedding Similarity Analysis)

- 목적: ViT의 Positional Embedding이 패치 간 위치 관계를 얼마나 잘 학습했는지 평가.
- 방법:
- 각 패치의 Positional Embedding을 코사인 유사도 히트맵으로 표현.
- -번째 행과 j-번째 열의 값은 두 패치 위치 간 유사도.
- 결과:
- 가까운 패치일수록 높은 유사도를 보임.
- 같은 열과 같은 행 내에서도 높은 유사도.
- 1D Positional Embedding만으로도 2D 이미지 위상을 잘 파악.
- ViT는 추가적인 2D 구조 정보 없이도 위치 관계를 효과적으로 학습.
3. Attention Distance 분석

- 목적: Self-Attention 메커니즘이 이미지의 전역적 특성과 지역적 특성을 어떻게 학습하는지 평가.
- 방법:
- Attention Weight를 기반으로 Mean Attention Distance를 계산:
- 각 픽셀이 주목하는 영역(거리)의 평균.
- CNN의 Receptive Field 개념과 비교.
- Attention Weight를 기반으로 Mean Attention Distance를 계산:
- 결과:
- ViT는 첫 번째 레이어부터 전역적 특성(Global Features) 학습 가능.
- 깊은 레이어로 갈수록 대부분의 Attention Head가 전역적 특성을 잘 포착.
- 최종적으로는 분류 작업에 중요한 부분을 집중적으로 학습.
5. Experiments
5.1 Datasets
- Pretraining:
- ImageNet-21k (14M 이미지), JFT-300M (303M 이미지).
- Downstream Tasks:
- ImageNet, CIFAR-10/100, VTAB(19개 Task 포함).
5.2 Results
- Accuracy:
- ImageNet: 88.55%, CIFAR-100: 94.55%.
- Comparison with SOTA:
- 대규모 데이터셋에서 ViT는 ResNet 기반 CNN보다 우수한 성능.
6. Conclusion

- 기여:
- Transformer를 Image Recognition에 성공적으로 적용.
- CNN 대비 Inductive Bias가 약하지만, 대규모 데이터셋으로 극복.
- Task-Agnostic 구조로 높은 확장성과 유연성 제공.
- 한계:
- Segmentation, Detection 등 다른 Vision Task에 대한 적용은 추가 연구 필요.
- Self-Supervised Learning 방법론의 최적화 필요.