SqueezeNet 논문 링크: [1602.07360] SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Recent research on deep neural networks has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multiple DNN architectures that achieve that accuracy level. With equivalent accuracy, smaller DNN archite
arxiv.org
ShuffleNet 논문 링크: https://arxiv.org/abs/1707.01083?utm_source=chatgpt.com
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group con
arxiv.org
OUTTA 논문 리뷰 링크: [2024-2] 박서형 - SqueezeNet, ShuffleNet
[2024-2] 박서형 - SqueezeNet, ShuffleNet
https://arxiv.org/abs/1602.07360 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and Recent research on deep neural networks has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multipl
blog.outta.ai
SqueezeNet
1. Introduction and Motivation
- Motivation
- AlexNet과 유사한 정확도를 유지하면서 모델 크기를 크게 줄이는 것이 목표
- 모바일·임베디드 등 제한된 환경에서도 딥러닝 모델 활용 가능하도록 설계
- Advantages
- 파라미터 수를 AlexNet 대비 50배 감소
- 모델 크기를 0.5MB 미만으로 압축
- 동일 수준의 정확도 제공
2. Related Work
- 기존 대형 모델(AlexNet, VGG, ResNet 등): 높은 정확도지만 메모리·연산량이 많아 제한이 큼
- 경량 모델: 모바일 기기에서 딥러닝 활용 가능
- SqueezeNet은 모델 크기와 정확도 균형을 추구하며 설계
3-1. Architectural Design Strategies
- 목표: 적은 파라미터로도 경쟁력 있는 정확도 유지
- 3×3 필터를 1×1 필터로 대체
- 3×3 대비 9배 적은 파라미터
- 3×3 필터 입력 채널 수 감소
- squeeze layer(1×1 Conv)로 입력 채널 먼저 줄이기 → 파라미터 추가 감소
- 초기 레이어 다운샘플링 지연
- 초반부에 다운샘플링을 늦춤 → 더 큰 해상도로 특징 추출
- 후반부에만 풀링하여 정확도 유지
3-2. The Fire Module

- (1) squeeze 단계:
- 1×1 Conv 필터만 사용 → 입력 채널 수 감소
- (2) expand 단계:
- 1×1 + 3×3 Conv를 조합해 특징 맵 확장
- Hyperparameter:
- $s_{1×1}$: squeeze 레이어 1×1 필터 수
- $e_{1×1}, e_{3×3}$: expand 레이어 1×1·3×3 필터 수
- 예) $s_{1×1}$을 작게 설정하면, 3×3 필터가 받는 채널 수가 줄어 파라미터 절감
3-3. The SqueezeNet Architecture

- Conv1 → Fire2~Fire9(총 8개 Fire 모듈) → Max-pooling(중간/후반부) → Conv10
- 다운샘플링 전략:
- 중·후반에만 Max-pooling으로 입력 크기 축소
- 초반에는 다운샘플링을 늦춰 고해상도 특징을 유지
4. Other SqueezeNet Details
- Zero-padding:
- Expand 모듈의 3×3 Conv는 패딩=1 → 1×1 Conv와 출력 크기 동일 유지
- Activation:
- 모든 Squeeze·Expand 레이어에 ReLU 적용
- Dropout:
- Fire9 이후에 50% Dropout 적용 → 과적합 방지
- No Fully-connected Layers:
- NiN(Network in Network) 아이디어 활용 → 완전연결층 제거
- Learning Rate Decay:
- 초기 0.04 → 점진적 감소(선형 스케줄)
- learning rate 줄이는 이유
- 초기에는 변하는 loss 값을 빠르게 봄.
- 초기에는 보폭을 크게 하여 local minimum을 탈출하기 위함.
- learning rate 줄이는 이유
- 초기 0.04 → 점진적 감소(선형 스케줄)
- Caffe Framework 구현:
- Expand 레이어를 내부적으로 1×1 Conv와 3×3 Conv 두 개로 분리 → 최종 출력 채널을 합침
5. 결론
- ImageNet에서 AlexNet과 동등 정확도 달성
- 모델 크기: AlexNet 대비 510배 작음(정확도 유사)
- 압축 후 모델 크기: 0.5MB 미만
- 의의:
- 경량 모델 설계의 새로운 기준 제시
- 높은 정확도 유지하며 모델 크기 대폭 감소 → 제한된 하드웨어 환경에서도 딥러닝 활용 가능성 확대
ShuffleNet
1. Introduction
- 목표: 모바일 장치(드론, 로봇, 스마트폰 등)에서 매우 제한된 계산량(수십~수백 MFLOPs)으로 최적 정확도 달성
- 핵심 아이디어
- Pointwise Group Convolution: 1×1 Conv의 계산 복잡도 감소
- Channel Shuffle: 그룹 합성곱으로 단절된 채널 간 정보 흐름을 복원
2-1. Channel Shuffle
- 1×1 Conv에서도 Group Convolution 적용 → 연산량 감소
- 여러 그룹을 쌓아 나갈 때 특정 채널이 한정된 입력에만 연결 → 정보 흐름 제한
- Channel Shuffle 연산을 도입 → 서로 다른 그룹끼리 채널을 섞어 정보 분산
- 계산 오버헤드 적으면서 표현력을 높임
2-2. ShuffleNet Unit
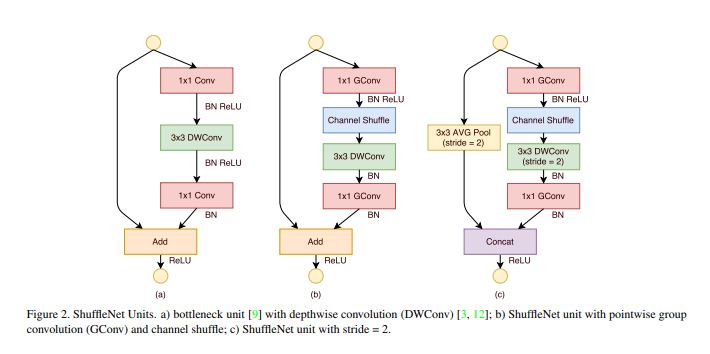
- 기존 Bottleneck 유닛 기반으로 설계
- 1×1 Conv를 그룹 합성곱으로 바꾸고, 그 뒤 Channel Shuffle 추가
- 두 번째 1×1 Conv로 채널 차원 복원
- ResNet/ResNeXt 대비 더 가볍고, 작은 네트워크에 최적
- 깊이별 합성곱은 보틀넥 맵에서만 실행 → 계산량 최소화
2-3. Network Architecture

- 다수의 ShuffleNet Unit으로 구성, 3단계로 나뉨
- 각 단계의 첫 블록에서 Stride=2로 다운샘플링
- 단계별 출력 채널 수 2배 증가, 보틀넥 채널은 출력 채널의 1/4
- 그룹 수(g)를 늘려도 계산 비용은 일정 부분 유지, 효율적 출력 가능
- 스케일링 팩터로 채널 수 조절 → 네트워크 복잡도 조정
- 결과적으로 계산 효율 유지하며 정보 인코딩 극대화 → 작은 모델에서도 우수 성능