AlexNet 논문 링크: ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
R-CNN 논문 링크: [1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. I
arxiv.org
VGGNet 논문 링크: [1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org
ResNet 논문 링크: [1512.03385] Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
OUTTA 논문 리뷰 링크:
[2024-2] 이재호 CNN의 역사 1 (2012~2015)
[2024-2] 이재호 CNN의 역사 1 (2012~2015)
이번 포스팅에서는 2012년부터 2015년에 이르기까지 CNN의 다양한 모델들에 대해 알아보겠습니다. # 목차1. AlexNet (2012)2. RCNN (2013)3. VGGNet (2014)4. ResNet (2015) # AlexNet - ImageNet Classification with Deep Convo
blog.outta.ai
1. AlexNet (2012)

개요
- 2012년 ILSVRC 대에서 2등과 10% 이상의 성능 차를 내며 우승
- 당시 1~2% 차이로 우승이 가려지던 대회에서 압도적 우승을 거둠
- 모델 구조: 5개의 Convolution Layer + 3개의 Fully-connected Layer (총 8개 Layer)
- GPU 병렬화(GTX580 2개)로 대규모 네트워크 훈련
주요 기법
1. ReLU 활성화 함수

- 기존 tanh/sigmoid 대비 Saturation 구간이 없어 학습 속도와 성능 향상
- 같은 정확도 유지 시 약 6배 빠른 학습 가능
2. Training on multiple GPU
- GPU 두 대를 병렬로 사용하여 네트워크 크기에 대한 한계 극복
- 특정 Convolution Layer에서만 GPU 간 통신
3. Local Response Normalization (LRN)
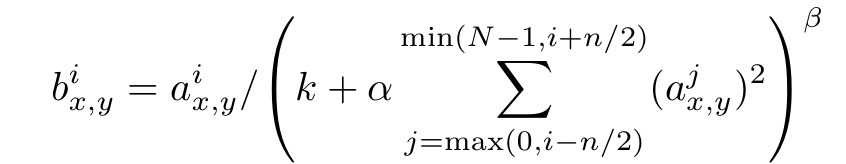
- 주변 커널들의 값 제곱합으로 나누어 뉴런 값 폭주 억제 및 일반화(generalization) 향상
4. Overlapping Pooling

- Pooling kernel을 겹치게 사용
- Top-1/Top-5 error 감소 & 과적합 크게 유발하지 않음
5. Data Augmentation
- Image translation & Horizontal flip: 256×256에서 224×224 부분 이미지를 추출 후 좌우 반전 → 데이터셋 2048배 증가
- RGB 채널 변환(PCA): 밝기·색상 변화에도 견고한 특징 학습
6. Dropout

- 학습 시 0.5 확률로 뉴런 출력 0 처리 → 과적합 감소
- 테스트 시에는 모든 뉴런 사용하되 출력값에 0.5 곱 적용
성과
- ILSVRC 2012에서 Top-1 error: 37.5% / Top-5 error: 15.3%
(2위 모델 Top-5 error: 26.2%)
2. R-CNN (2013)

개요
- CNN을 Region Proposal에 결합하여,
- 이미지 분류(AlexNet 등)에서만 두드러진 CNN을 객체 탐지까지 확장
- SIFT, HOG 등 기존 객체 탐지보다 월등한 성능 달성
작동 순서
- Selective Search로 약 2000개의 Region Proposal 추출
- 각 Region Proposal을 227×227 크기로 Warp
- Fine-tuned된 AlexNet(CNN)에 각 Region을 넣어 4096차원 특징 벡터 추출
- 추출된 벡터를 Linear SVM 및 Bounding Box Regressor에 입력
- SVM: 각 Region이 특정 클래스에 속할 확률(결정 점수) 산출
- Bounding Box Regressor: 후보 영역(Bounding box) 위치 보정
- 후보 영역에 대한 최종 예측
성과
- PASCAL VOC 2010: mAP 53.7% (기존 최고 성능: 35.1%)
- ILSVRC 2013 객체 검출: 기존 OverFeat보다 우수
결론
- Pre-training + Fine-tuning 결합 시, 데이터가 적어도 높은 성능 가능
- Selective Search + CNN 결합이 객체 탐지에 효과적임을 입증
3. VGGNet (2014)
개요
- 기존 모델(AlexNet 등)은 상대적으로 얕은 구조(5~8 Layer) & 큰 필터 사용
- VGGNet은 3×3 필터만 고집하며 네트워크 깊이 확장 → 높은 성능
구조
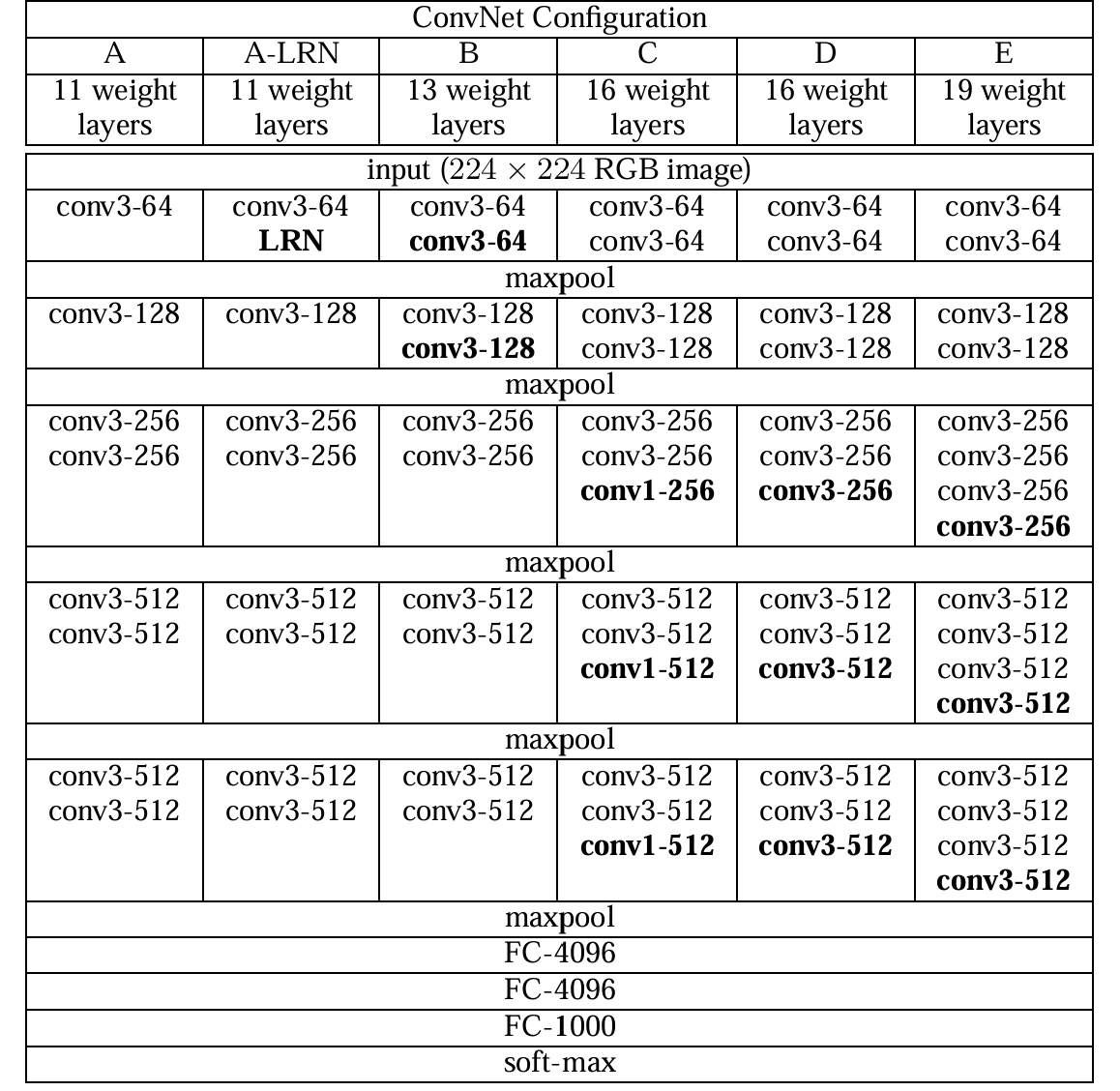
- 3×3 Convolution(Stride 1)를 반복적으로 사용
- Fully-connected Layer 3개
- ReLU 활성화 함수 사용
- 16~19개의 Layer 등 여러 버전 존재
3×3 필터만 사용하는 이유

- 층을 깊게 쌓을 수 있음
- 예: 7×7 필터 한 번 vs. 3×3 필터 세 번 → 출력 맵 크기 동일
- 파라미터 수 감소 → 학습 효율성 상승
- 비선형성 증가
- 매 Convolution 후 ReLU 적용 → 깊이 증가 효과 극대화
성과
- ILSVRC 2014에서 Top-5 error: 7.3%
- GoogLeNet(6.7%)에 이어 2위
- 간단한 구조로 다양한 응용에 적합
결론
- 네트워크 깊이 확장을 통해 딥러닝 성능 극대화 가능성 제시
4. ResNet (2015)
개요
- 딥러닝 모델은 깊어질수록 복잡한 특징 학습 가능하지만,
- Gradient Vanishing(기울기 소실) 문제로 오히려 성능 감소 가능
- ResNet은 Residual Learning을 통해 이를 해결
Residual Learning

\[ H(x) = F(x) + x \]
- H(x): 네트워크가 학습해야 할 목표 함수
- F(x) = H(x) - x (잔차)만 학습 → 학습 부담 감소
- Identity shortcut connection으로 추가 파라미터 없이 간단 구현
- Gradient Vanishing 해결:
- \[ \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \Bigl(\frac{\partial F(x)}{\partial x} + 1\Bigr) \]
- 기울기에 1이 더해져서 소실 방지
구조

- VGG19 기반 Convolution Layer + Shortcut Connection 조합
- 더 깊어졌음에도 연산량 감소 + 성능 향상(Residual Learning)
성과

- Plain Network(잔차 없이 단순 깊이만 증가)의 성능은 층이 깊어질수록 감소
- ResNet은 층이 깊어져도 성능 오히려 증가
- ILSVRC 2015에서 Top-5 error: 3.57%로 1위
결론
- Residual Learning 통해 딥러닝 네트워크 깊이 혁신적 확장 가능성 시사
위 내용을 토대로,
- CNN 모델들이 어떻게 발전해 왔는지(깊이, Residual Learning, Region Proposal 등)
- 주요 기술(Overlapping Pooling, Local Response Normalization, Data Augmentation, Shortcut Connection 등)
- 딥러닝 성능 향상 및 한계 극복 방법
을 간단 명료하게 알 수 있다.