논문 링크: https://arxiv.org/pdf/1609.04802.pdf
1. Abstract & Introduction

배경 및 문제점

- 기존 초해상도(SR) 모델은 주로 CNN을 사용하며, MSE 기반 손실 함수를 통해 PSNR 개선에 집중해 왔음.
- 그러나 MSE는 고해상도 이미지를 만들 때 사람의 지각(perceptual) 능력을 반영하기 어렵고, 고주파수 디테일(finer texture)을 복원하기에 부적합.
- 예를 들어, 이미지가 1픽셀 평행 이동만 되어도, 사람은 비슷해 보이지만 MSE는 크게 달라진 값으로 계산하여 스무딩(smoothing) 현상 발생.
핵심 아이디어
- 사람이 느끼는 지각적 고화질(perceptual quality)을 재현하기 위해,
- GAN 구조(SRGAN): 진짜 같은 이미지를 생성하도록 생성자-판별자를 학습
- 지각적 손실 함수(Perceptual Loss):
- Adversarial Loss(GAN 생성자 손실)
- Content Loss(VGG19로부터 추출된 Feature Map 간의 MSE)
- 새로운 평가 방식(MOS): PSNR 대신 사람의 주관 평가(1~5점)를 활용
이로써 고주파수 질감을 복원하며, 사람이 보기에 고해상도처럼 느껴지는 이미지를 생성 가능함.
2. Method
(1) 학습 데이터 구성
- 고해상도(HR) 이미지를 가우시안 필터 + 다운샘플하여 저해상도(LR) 이미지를 생성
- (LR, HR) Paired Data로 학습
- $r = 4$ 배로 축소하여, 4× 업스케일 문제 설정
(2) SRGAN의 목적 함수
(a) 판별자(Discriminator) 손실

- 일반적인 GAN과 동일하게 진짜 이미지는 1, 가짜 이미지는 0으로 분류하도록 학습
- $$\max_D \, \Bigl[\log D(\text{I}_{HR}) + \log(1 - D(\text{I}_{SR}))\Bigr]$$
(b) 생성자(Generator) 손실

- Adversarial Loss
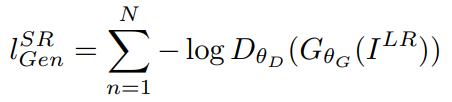
- 판별자를 속여서 진짜 같은 고해상도 이미지를 만들어내도록 유도
- Content Loss(VGG Loss)

- 사전 학습된 VGG19의 중간 레이어에서 뽑은 Feature Map 간의 MSE
- 가짜 $\text{I}_{SR}$와 진짜 $\text{I}_{HR}$의 ‘지각적 차이’를 최소화
따라서 최종 지각적 손실은
$$\mathcal{L}_{\text{SRGAN}} = \mathcal{L}_{\text{content}} + \lambda \,\mathcal{L}_{\text{adversarial}},$$
와 같은 가중치 합으로 구성됨.
(3) SRGAN 아키텍처

(a) 생성자(Generator)

- Residual Blocks(3×3 Conv, Skip Connection) + PixelShuffler(×2 업스케일) 2개 → 결과적으로 4× 업스케일
- 맨 마지막에 Upsampling을 수행해 연산량 절감
- PReLU 활성함수, Batch Normalization 등 사용
(b) 판별자(Discriminator)

- 3×3 필터, 점차 증가하는 채널(64→128→256→512)
- 마지막에 Dense + Sigmoid로 이진 분류
- 실용적 구현에 따라 Dense Layer 대신 Global Pooling 대체 가능
3. Experiments
(1) 학습 설정
- ImageNet에서 임의 샘플한 약 35만 장으로 학습, Set5·Set14·BSD100 등으로 테스트
- 다운샘플(4×)로 LR 이미지 생성, HR 이미지는 96×96 Crop
- 최적화: Adam($\beta_1=0.9$)
- SRResNet(백만 iteration) → 이후 SRGAN(총 20만 iteration) 단계적 학습
- 생성자, 판별자 교대로 학습(k=1)
(2) 평가 방식

- MOS(Mean Opinion Score): 26명 평가자가 1~5점으로 점수 매김
- 기존 PSNR/SSIM은 MSE 기반이라, 지각적 품질을 반영하지 못한다는 문제를 지적
(3) 결과

- SRGAN이 기존 기법보다 미세 질감 표현 우수
- MOS 점수에서 SRGAN-VGG54 버전이 가장 높은 점수 획득
- PSNR은 다소 낮을 수 있으나, 사람이 보기엔 더 고화질에 가깝게 인지
4 & 5. Discussion, Future Work & Conclusion
- Residual Network 기반의 SRResNet을 통해 SOTA 달성 → MSE 기반 측정(PSNR) 개선
- GAN + VGG Loss를 결합한 SRGAN은 지각적 품질 측면에서 큰 도약
- 4× 업스케일링에서 SRGAN이 가장 현실감 있고, 사람의 선호도가 높은 이미지 생성
- 향후에는 업스케일 팩터를 더욱 키우거나, 다른 perceptual 손실·컨디셔닝 방법까지 고려 가능
- 저자들은 “최적의 손실 함수는 ‘해상도 목표·응용 분야’에 따라 달라질 수 있음”을 언급
요약
- 문제의식: 기존 SR 기법은 MSE에 치중 → 고주파 디테일 및 지각적 품질이 부족.
- 핵심 기여:
- GAN을 활용한 SRGAN 아키텍처로 4× 업스케일링 구현
- 지각적 손실(Perceptual Loss)로 Adversarial Loss + VGG Loss 사용
- PSNR/SSIM 대신 MOS를 통해 사람이 느끼는 품질 평가
- 결론:
- SRGAN은 인간 시각적 선호도를 반영한 고화질·고주파 디테일 복원에 성공, 초해상도 분야의 한계를 크게 개선.