SRCNN 논문 링크: https://arxiv.org/abs/1501.00092
Image Super-Resolution Using Deep Convolutional Networks
We propose a deep learning method for single image super-resolution (SR). Our method directly learns an end-to-end mapping between the low/high-resolution images. The mapping is represented as a deep convolutional neural network (CNN) that takes the low-re
arxiv.org
ESRGAN 논문 링크: [1809.00219] ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
The Super-Resolution Generative Adversarial Network (SRGAN) is a seminal work that is capable of generating realistic textures during single image super-resolution. However, the hallucinated details are often accompanied with unpleasant artifacts. To furth
arxiv.org
(1) SRCNN은 딥러닝 기반 초해상도(Super-Resolution) 모델의 시작점으로,
(2) ESRGAN은 SRGAN을 향상시킨 모델로 보다 사실적인(Perceptually Pleasing) 이미지 복원을 목표로 함.
1. SRCNN (ECCV 2014)
1.1 배경 및 의의
- SR(Super Resolution)은 저해상도 이미지를 고해상도로 복원하는 전통적인 문제로, 예전에는 예시 기반(example-based), sparse coding 등을 사용.
- SRCNN은 간단한 CNN 구조만으로도 기존 전통 방법(bicubic, sparse coding 등)을 뛰어넘는 성능 및 속도를 달성.
- 이후 등장하는 딥러닝 기반 SR 모델들의 시초가 됨.
1.2 모델 구조
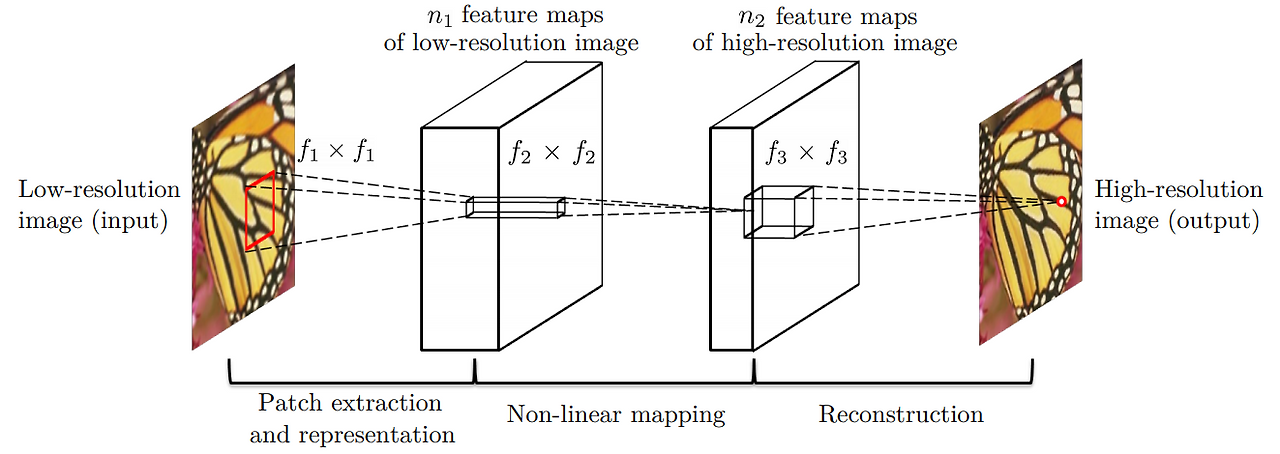
- Bicubic Upsampling (전처리)

원본 RGB 이미지를 YCbCr로 바꾸고 Y 채널만 사용하기 - 저해상도 이미지를 미리 원하는 해상도로 2×, 3×, 4× 등으로 보간(upscale)
- 3단계 CNN
- (1) Patch extraction & representation

- 첫 번째 Conv+ReLU 레이어가 저해상도 이미지로부터 국소(패치) 특징을 추출, 고차원 벡터로 표현
- (2) Non-linear mapping

- 두 번째 Conv+ReLU 레이어가 앞 단계의 특징을 다른 고차원 표현으로 매핑
- (3) Reconstruction

- 세 번째 Conv 레이어가 이 표현들을 합쳐 최종 고해상도 이미지를 복원
- (1) Patch extraction & representation
- 결과적으로, “Input → Conv+ReLU → Conv+ReLU → Conv → Output” 형태의 얕은 CNN 구조

CNN 관점에서 본 sparse coding method
1.3 학습 및 손실 함수
- MSE(Mean Squared Error) 기반 손실
- 학습 시, 원본 이미지를 sub-image(패치)로 잘라 사용
- 평가 지표: PSNR, SSIM(특히 Y 채널 위주)

MSE 및 PSNR
1.4 실험 결과
- 속도 & 정확도
- 기존 Sparse coding, Bicubic, 다른 전통 기법 대비 PSNR과 실행 속도 모두 우수
- CPU에서도 빠른 복원이 가능
- 특징
- 모델이 간단한 구조이지만 고성능
- 더 큰 데이터셋에서 학습할수록 성능이 증가
- 1채널(Y)뿐 아니라 RGB 3채널 전체도 처리 가능
2. ESRGAN (2018)
2.1 배경

- SRGAN(2017)에서 GAN + VGG Loss를 결합해 지각적 품질(Perceptual Quality)을 크게 향상했으나,
- 여전히 HR 이미지와 비교 시 질감 표현이 부족, artifact 발생 가능
- ESRGAN은 SRGAN을 Residual-in-Residual Dense Block, Relativistic GAN, 수정된 Perceptual Loss 등으로 개선해 더 사실적인 디테일을 생성
2.2 주요 기법
(1) Residual-in-Residual Dense Block (RRDB)



- 트레이닝·테스트 세트의 통계 차이로 인한 artifact 방지 & 연산량 절감
- BN이 에지(edge) 표현 등에서 range flexibility를 떨어뜨려 부드럽게(blurry) 되는 문제 회피
- Dense connection과 Residual connection을 중첩
- 더 깊은 표현 학습, 풍부한 특징 추출
- SRResNet 구조에서 블록만 대체 → “RRDB”로 구성된 깊은 네트워크
(2) Relativistic GAN


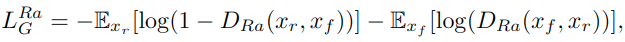
- 기존의 GAN 판별자는 “이 이미지가 Real or Fake?”만 판단
- Relativistic 평균 GAN(RaGAN)은 “이 가짜가 Real보다 얼마나 진짜 같은가” 식으로 정의

- Real 샘플도 생성자 업데이트 시 영향을 주어, 더 풍부한 시각적 품질 유도
- 결과적으로 디테일이 선명해지고, texture가 자연스러워짐
(3) Perceptual Loss 개선
- 이전 SRGAN: VGG19의 activation 이후 Feature Map 사용

(상) before activation, (하) after activation - 심층 레이어 → 특징 희박화(sparsity) 발생, supervision이 약해지는 문제
- ESRGAN: activation 이전 Feature Map 사용

- 더 강력한 gradient 전달, 밝기 복원에도 유리
- 일부 실험에서는 classification용 VGG 대신 material recognition으로 미세조정된 VGG 사용 → 디테일 개선
(4) Network Interpolation

- GAN 기반 학습 시, Perceptual Quality는 좋으나 artifact가 생길 수 있음
- PSNR-oriented 가중치($\theta_{\text{PSNR}}$)와 GAN-oriented 가중치($\theta_{\text{GAN}}$)를 가중 조합

- 사용자 선호도에 따라 α\alpha를 조절해 디테일 vs. 안정성 균형
2.3 Total Loss

- $\mathcal{L}_{1}$: 초기 학습 단계에서 L1로 지역 최적화 회피 및 안정적 학습
- $\mathcal{L}_{\text{RaGAN}}$: Relativistic 판별자의 손실
- $\mathcal{L}_{\text{Perceptual}}$: VGG19(activation 이전) Feature Map 기준 차이
2.4 실험 결과

- 벤치마크(DIV2K 등)에서 PSNR, SSIM은 무조건 최고는 아니지만,
- 시각적으로 훨씬 세밀하고 선명한 질감 표현
- GAN 기반 모델 특성상 “객관 척도”와 “주관 척도(시각적 품질)” 사이 트레이드오프 존재 → ESRGAN은 주관적으로 더 선호됨
3. 비교 요약
| 구분 | SRCNN | SRGAN |
| 발표 시기 | ECCV 2014 | 2018 (SRGAN 후속) |
| 주요 특징 | - 딥러닝 기반 SR 시초 - 간단한 3레이어 CNN |
- SRGAN 개선판 - RRDB 블록 + Relativistic GAN + 새로운 Perceptual Loss |
| 손실 함수 | - MSE | - RaGAN Loss + VGG19(activation 이전) + L1 |
| 장점 | - 연산 빠름, 구조 간단 - 전통 기법 대비 높은 PSNR |
- 더 세밀한 디테일 - 시각적으로 “사람이 보기에” 고품질 |
| 한계 | - 지각적 품질 부족 - 고주파 부분 스무딩 |
- PSNR, SSIM은 낮을 수 있음 - GAN 특성의 artifact 가능 |
4. 결론
- SRCNN은 딥러닝 기반 초해상도의 시초로, 전통 방법을 모두 뛰어넘는 간단하지만 고성능 모델을 제안.
- 이후 GAN 기법이 도입되며 SRGAN, 그리고 더욱 개선된 ESRGAN이 등장해, 지각적 품질(Perceptual Quality)을 대폭 향상.
- ESRGAN은 BN 제거, Residual-in-Residual Dense Block, Relativistic GAN, 수정된 Perceptual Loss 등을 통해 시각적으로 가장 자연스러운 SR 결과를 보여줌.
정리하자면,
- SRCNN: “딥러닝 기반으로 SR 전 과정을 통합적으로 학습” → 전통 방법보다 뛰어난 PSNR, 속도도 빠름.
- ESRGAN: “SRGAN을 한층 발전” → 실제와 가까운 디테일, Perceptual Quality를 크게 개선하여 고화질 초해상도에 탁월.
이로써 Super-Resolution 분야는 “객관 척도(PSNR/SSIM) vs. 지각 척도(Perceptual Quality)”라는 두 축에서 연구가 활발해졌으며, ESRGAN은 아직도 시각적으로 가장 선호되는 SR 모델 중 하나로 꼽힘.