논문 링크: 1902.01019
저자: Shervin Minaee (Expedia Group), Amirali Abdolrashidi (University of California, Riverside)
발행일: 2019. 2. 4
Abstract
얼굴 표정 인식(Facial Expression Recognition, FER)은 지난 수십 년 동안 활발히 연구되어 온 분야이며, 여전히 높은 intra-class variation(동일한 감정이라도 다양한 표정이 존재하는 문제) 때문에 어려운 과제이다.
기존 방법들은 SIFT, HOG, LBP와 같은 hand-crafted feature(사전에 정의된 특징)를 추출한 후, 특정 이미지 또는 비디오 데이터베이스에서 학습된 분류기를 사용하여 얼굴 표정을 인식하는 방식이 주로 사용되었다.
그러나 이러한 전통적인 접근법은 제어된 환경에서 수집된 데이터셋에서는 좋은 성능을 보이지만, 더 다양한 이미지 변형(illumination 변화, occlusion 등)이나 얼굴 일부가 가려진 데이터에서는 성능이 저하되는 문제가 있다.
최근에는 딥러닝을 이용하여 end-to-end 방식의 얼굴 표정 인식 시스템이 개발되었으며, 기존보다 성능이 개선되었지만, 여전히 추가적인 성능 향상의 여지가 존재한다.
이에 본 연구에서는 attention 기반 합성곱 신경망(Attentional Convolutional Network, ACN)을 적용한 딥러닝 모델을 제안한다.
이 모델은 얼굴의 중요한 부분(salient regions) 에 집중하여 표정 인식 성능을 향상시키며, FER-2013, CK+, FERG, JAFFE와 같은 여러 데이터셋에서 기존 모델 대비 높은 성능을 보인다.
또한, 모델이 얼굴에서 감정 인식을 위해 중요한 영역을 어떻게 선택하는지 시각화하는 기법을 적용하여, 감정마다 중요한 얼굴 부위가 다를 수 있음을 실험적으로 증명하였다.
1. Introduction
감정(emotion)은 인간 상호작용에서 필수적인 요소이다. 감정은 다양한 방식으로 표현될 수 있으며, 육안으로 감지되지 않는 경우도 많다. 따라서 적절한 도구를 사용하면 감정을 분석하고 인식할 수 있다.
최근 몇 년간 사람의 감정을 자동으로 인식하는 기술의 필요성이 증가하고 있으며, 감정 인식은 다음과 같은 다양한 분야에서 활용되고 있다.
- 인간-컴퓨터 인터페이스(Human-Computer Interface)
- 애니메이션(Animation)
- 의료(Medicine)
- 보안(Security)
감정 인식은 얼굴(Face), 음성(Speech), 뇌파(EEG), 텍스트(Text) 등의 다양한 신호를 이용하여 수행될 수 있다.
그중에서도 얼굴 표정(Facial Expression) 은 감정 인식에서 가장 널리 사용되는 방법 중 하나이다.
그 이유는 다음과 같다.
- 눈으로 직접 볼 수 있는 신호(Visible)
- 감정 인식에 유용한 많은 특징 포함(Feature-rich)
- 대량의 얼굴 이미지 데이터 수집이 상대적으로 용이(Easy to collect large datasets)
딥러닝, 특히 합성곱 신경망(Convolutional Neural Networks, CNNs) 이 등장하면서 얼굴 표정에서 더욱 강력한 특징을 학습할 수 있게 되었으며, 기존 기법보다 높은 성능을 달성할 수 있었다.
그러나 얼굴 표정에서 감정을 구분할 때, 얼굴 전체가 아니라 입, 눈 등 일부 부위가 결정적인 역할을 하는 반면, 귀나 머리카락과 같은 영역은 상대적으로 중요하지 않다.
따라서 이상적인 모델은 얼굴에서 중요한 부분만 집중적으로 학습하고, 나머지 부분에는 덜 민감하게 반응해야 한다.
본 논문에서는 attention mechanism 을 활용하여 중요한 얼굴 영역에 집중하는 딥러닝 모델을 제안한다.
이 연구의 주요 기여(contributions)는 다음과 같다.
- 주의 기반 합성곱 신경망(Attentional Convolutional Network) 제안
- 얼굴에서 감정 분류에 중요한 부분만 선택적으로 활용
- 기존 연구보다 더 높은 정확도 달성
- 시각화 기법을 적용하여 얼굴 이미지에서 중요한 영역을 분석
- 감정마다 얼굴에서 중요한 부위가 다름을 실험적으로 증명
- 논문 Fig. 1에 감정별 중요한 얼굴 부위 예시 제공

Fig. 1
2. Related Works

얼굴 표정 인식(FER)의 대표적인 연구 중 하나는 Paul Ekman의 연구로, 인간의 기본적인 감정을 행복(Happiness), 슬픔(Sadness), 분노(Anger), 놀람(Surprise), 공포(Fear), 혐오(Disgust) 등 6가지 감정으로 정의했다. 이후 연구에서 중립(Neutral) 감정을 추가하여 총 7가지 기본 감정이 되었다.
Ekman은 이 개념을 바탕으로 FACS(Facial Action Coding System) 를 개발하여, 이후 감정 인식 연구에서 표준이 되었다.
기존 감정 인식 연구의 흐름
초기의 감정 인식 연구는 전통적인 기계 학습 기반 2단계 접근법을 사용했다.
- Feature Extraction: 이미지에서 특정 특징을 추출
- HOG (Histogram of Oriented Gradients)
- LBP (Local Binary Patterns)
- Gabor Wavelets
- Haar Features
- Classification: 추출된 특징을 기반으로 감정을 예측
- SVM (Support Vector Machine)
- Random Forest
- Neural Network
이러한 접근법은 비교적 단순한 데이터셋(제어된 환경에서 수집된 데이터) 에서는 잘 동작했지만, 더 복잡하고 다양한 얼굴 표정이 포함된 데이터셋에서는 한계를 보였다. 예를 들어, FER 데이터셋에서 얼굴이 부분적으로 가려진 경우(occlusion) 나 안경 등의 방해 요소 가 있을 때 성능이 저하되었다.
딥러닝 기반 감정 인식 연구
딥러닝, 특히 합성곱 신경망(CNNs) 이 이미지 분류 및 컴퓨터 비전 문제에서 큰 성공을 거두면서, 감정 인식에도 CNN 기반 접근법이 적용되었다.
대표적인 연구들은 다음과 같다.
- Khorrami (2016): CNN을 사용하여 높은 감정 인식 정확도를 달성. CK+ 및 TFD 데이터셋에서 최첨단 성능(State-of-the-Art)을 기록함.
- Aneja et al. (2017): 딥러닝을 사용하여 애니메이션 캐릭터의 얼굴 표정 모델링을 수행.
- Mollahosseini (2016): CNN을 활용한 감정 인식 모델을 개발하여 CK+ 및 JAFFE 데이터셋에서 좋은 성능을 보임.
- Barsoum et al. (2016): Crowdsourcing을 이용해 데이터셋의 라벨을 수정한 후, Deep CNN 모델을 적용하여 높은 성능을 달성.
- Han et al. (2017): IB-CNN (Incremental Boosting CNN) 모델을 개발하여, 자연스러운(spontaneous) 얼굴 표정 인식 성능을 향상시킴.
- Meng (2017): IA-CNN (Identity-Aware CNN) 모델을 제안하여, 개인의 고유한 특징(identity) 과 표정(expression)의 차이 를 학습하는 대조 손실(Contrastive Loss)을 도입.
위 연구들은 기존 전통적 기법보다 훨씬 높은 성능을 보여주었으나, 얼굴에서 감정을 결정하는 중요한 영역에 집중하는 메커니즘(attention mechanism)이 부족 하다는 문제가 있었다.
이에 본 연구에서는 주의 기반 합성곱 신경망(Attentional Convolutional Network, ACN) 을 제안하여, 감정을 예측하는 데 중요한 얼굴 영역에 집중할 수 있도록 개선하였다.
3. The Proposed Framework
본 논문에서는 주의 기반 합성곱 신경망(Attentional Convolutional Network, ACN) 을 적용한 end-to-end 딥러닝 모델을 제안한다.
일반적으로 CNN 성능을 개선하는 방법에는 다음과 같은 기법들이 있다.
- 더 깊은 네트워크 (Deeper Network) → 더 많은 계층 추가
- Gradient Flow 개선 (e.g., Skip Connections, ResNet)
- 더 강력한 정규화 적용 (e.g., Spectral Normalization, Dropout)
그러나 감정 인식은 클래스 수가 적은 문제(7가지 감정 분류) 이므로, 모델을 지나치게 복잡하게 만들 필요가 없다.
본 연구에서는 10개 미만의 CNN 계층과 주의 메커니즘(attention mechanism)을 적용하여 기존 최첨단 모델보다 더 높은 성능을 달성할 수 있음을 보였다.
1. Main Idea
- 감정 인식에는 얼굴의 일부 영역(입, 눈 등)이 더 중요하며, 머리카락, 귀 등은 크게 기여하지 않는다.
- 따라서, 공간 변환 네트워크(Spatial Transformer Network, STN) 를 적용하여 중요한 얼굴 부위에 집중할 수 있도록 설계.
2. Architecture

Fig. 3 에서 설명된 모델 구조는 다음과 같다.
- 특징 추출(Feature Extraction)
- 4개의 합성곱 계층(CNN Layers)
- 각 2개의 CNN 계층 후, Max-Pooling과 ReLU 적용
- Dropout 및 2개의 Fully Connected 계층 추가
- 공간 변환 네트워크(Spatial Transformer Network, STN)
- 2개의 합성곱 계층(CNN Layers)
- 각 계층 후 Max-Pooling과 ReLU 활성화 함수 적용
- Fully Connected Layers
- Affine 변환을 적용하여 얼굴의 중요한 부분을 강조
Affine 변환(Affine Transformation) 적용
STN을 통해 입력 이미지의 중요한 부분을 자동으로 찾아 변형(warping)하는데, Affine 변환(선형 변환 + 이동 변환)이 적용된다.
Affine 변환은 다양한 컴퓨터 비전 응용에서 널리 사용되는 변환 기법이며, 얼굴 표정 분석에도 유용하다.
1. Affine 변환 매개변수 $\theta$ 생성 (Localization Network)
- CNN을 통해 입력 이미지에서 얼굴의 중요한 부분(입, 눈 등)을 찾음
- Fully Connected (FC) Layer에서 Affine 변환 매개변수 $\theta$ 를 학습
- θ\theta 는 Scaling, Rotation, Translation(이동), Shearing(왜곡) 등의 변형을 포함하는 행렬
2. Grid Generator ($\tau_\theta(G)$) 가 변형된 좌표계를 생성
- θ\theta 를 기반으로 변형된 픽셀 위치를 결정하는 좌표(Grid)를 생성
- 즉, 원본 이미지에서 어느 부분을 가져올지 새로운 좌표계를 만듦
3. ⊗ 기호: Grid Sampling (Warping) 연산 수행
- Grid Generator ($\tau_\theta(G)$) 가 만든 변형된 좌표를 이용하여, 원본 이미지에서 해당 부분을 샘플링
- 이 과정에서 원본 이미지 픽셀을 새로운 좌표에 맞게 매핑하여 Warping된 새로운 이미지를 생성
📌 즉, ⊗는 단순한 연산 기호가 아니라, "STN이 원본 이미지에서 중요한 부분만 변형하여 CNN이 학습할 새로운 이미지를 생성하는 과정"을 의미!
왜 STN 결과로 CNN의 변형된 좌표값이 처음 CNN(Conv 4개 이전)으로 돌아가는 구조가 아키텍처에 안 나와 있나?
이 아키텍처 그림에서는 STN의 전체 과정이 생략되어 있기 때문
STN의 원래 동작 방식과 아키텍처 그림에서 생략된 부분
- STN의 원래 동작
- STN의 목적은 원본 이미지에서 감정 인식에 중요한 부분을 찾아 변형된 이미지를 CNN에 다시 입력하는 것
- 즉, STN이 만들어낸 변형된 이미지가 CNN의 Conv Layer로 다시 입력됨
- STN이 변형한 결과가 CNN Feature Extraction의 첫 번째 Convolution Layer로 들어가야 하는데, 이 부분이 그림에서는 표현되지 않음
- 아키텍처에서 빠진 부분
- 이 논문 아키텍처에서는 STN의 출력이 CNN의 첫 번째 Layer로 다시 들어가는 흐름을 생략
- 대신, Grid Generator ($\tau_\theta(G)$) 의 출력이 CNN Feature Extraction과 연결된 것처럼 보이게 단순화됨
- 즉, 원래는 "STN 결과 → CNN 첫 번째 Conv Layer 입력"이 되어야 하지만, 그림에서는 Grid Generator와 CNN 사이의 직접적인 관계만 강조함
최종 정리
1. ⊗ 기호는 Grid Sampling (Warping) 연산을 의미하며, STN이 변형된 이미지 좌표를 기반으로 샘플링하는 과정
2. STN의 변형된 결과는 CNN Feature Extraction에 다시 입력되지만, 아키텍처 그림에서는 이 과정이 명확히 표현되지 않음
3. 즉, STN의 변형된 좌표값(새로운 이미지)은 CNN 첫 번째 Convolution Layer로 다시 들어가지만, 그림에서는 생략됨
📌 즉, 그림이 STN의 전체적인 데이터 흐름을 100% 반영하지 않고 단순화했기 때문에, "STN 결과가 CNN 처음으로 다시 들어가는 구조"가 명확하게 표현되지 않은 것!
3. Training
- 모델 학습은 Adam Optimizer 를 사용하여 최적화함.
- Loss Function
- Cross-Entropy Loss
- L2 정규화 (Regularization Term, λ = 2-노름 적용)
$$L_{\text{overall}} = L_{\text{classifier}} + \lambda ||w||_2^2$$
- 정규화 항(Regularization Term) λ는 검증 데이터셋(validation set)에서 최적값을 조정(tuned)하여 적용.
- Dropout + L2 Regularization 적용으로 인해 작은 데이터셋(JAFFE, CK+ 등)에서도 효과적으로 학습 가능.
- 데이터셋마다 개별 모델을 학습함.
4. Results
- CNN 계층 수를 50개 이상으로 확장하는 실험도 진행했지만, 성능이 크게 향상되지 않음.
- 따라서 단순한 모델(10개 이하의 계층)이 최적의 성능을 제공하는 것으로 결론.
4. Experimental Results
본 섹션에서는 제안된 모델이 다양한 얼굴 표정 인식(FER) 데이터셋에서 어떻게 성능을 발휘하는지 실험적으로 분석한다.
다음과 같은 순서로 실험을 진행하였다.
- 사용한 데이터셋 개요
- 제안한 모델의 성능 분석 및 기존 연구와 비교
- 시각화 기법을 이용하여 모델이 감정 인식에서 중요하게 여기는 얼굴 영역 분석
A. Databases
본 연구에서는 4개의 대표적인 얼굴 표정 인식 데이터셋을 사용하였다.
1. FER2013 (Facial Expression Recognition 2013)

- ICML 2013 Challenges in Representation Learning에서 처음 공개됨.
- 총 35,887개의 48×48 해상도 이미지 포함.
- 대부분의 이미지가 야생 환경(wild settings) 에서 촬영됨.
- 데이터 구성:
- Train Set: 28,709개
- Validation & Test Set: 3,589개씩
- 구글 이미지 검색 API를 이용해 자동으로 얼굴이 정렬됨.
- 특징:
- 얼굴이 가려진 경우(occlusion, 손으로 얼굴을 가리는 경우 등)
- 부분적으로 잘린 얼굴(partial faces)
- 저대비(low-contrast) 이미지
- 안경을 쓴 얼굴(eyeglasses) 등 다양한 변형 포함 → 매우 도전적인 데이터셋
2. CK+ (Extended Cohn-Kanade Database)

- Action Unit(AU) 및 감정 인식을 위한 공개 데이터셋.
- 포즈된 얼굴(Posed Expressions)과 자연스러운 얼굴(Spontaneous Expressions)을 포함.
- 총 593개의 얼굴 시퀀스(123명의 피험자) 포함.
- 기존 연구에서는 일반적으로 시퀀스의 마지막 프레임(last frame) 만 사용하여 감정 인식을 수행.
3. JAFFE (Japanese Female Facial Expression Database)

- 10명의 일본 여성 모델이 7가지 표정을 연출한 총 213개 이미지로 구성됨.
- 60명의 일본 피험자가 6가지 감정 척도로 이미지에 감정을 부여.
4. FERG (Facial Expression Research Group Database)

- 애니메이션 스타일 캐릭터의 얼굴 표정 데이터셋.
- 총 55,767개 이미지 포함.
- 6명의 캐릭터 모델링(3D MAYA 사용)
- 7가지 감정 라벨이 제공됨.
- 애니메이션 캐릭터에서도 제안한 모델이 효과적으로 동작하는지 평가하기 위해 사용됨.
B. Experimental Analysis and Comparison
각 데이터셋별로 훈련(train), 검증(validation), 테스트(test) 세트를 나누어 모델을 학습하고, 성능을 측정하였다.
1. FER2013 데이터셋 성능 비교

- 총 28,709개의 훈련 데이터로 학습 후, 검증 및 테스트 세트(3,589개)에서 평가 수행.
- 제안한 모델은 70.02%의 정확도를 기록하며 기존 연구보다 높은 성능을 보임.
오차 행렬(Confusion Matrix) 분석

- 혐오(Disgust), 공포(Fear) 감정에서 오류가 많음.
- 이는 해당 감정들의 데이터 개수가 적기 때문.
- 반면, 행복(Happiness)과 중립(Neutral) 감정은 상대적으로 높은 정확도를 기록.
2. FERG 데이터셋 성능 비교


- 총 55,767개 이미지 중 34,000개를 훈련, 14,000개를 검증, 7,000개를 테스트에 사용.
- 각 감정별로 1,000개의 테스트 샘플을 랜덤으로 선택하여 평가.
- 제안한 모델은 99.3%의 정확도를 달성, 기존 연구보다 뛰어난 성능을 보임.
3. JAFFE 데이터셋 성능 비교
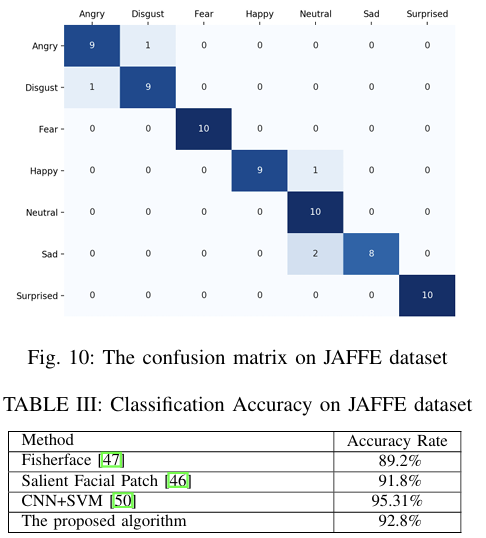
- 훈련: 120개, 검증: 23개, 테스트: 70개(각 감정당 10개)
- 제안한 모델은 92.8%의 정확도를 기록.
4. CK+ 데이터셋 성능 비교

- 전체 데이터의 70%를 훈련, 10%를 검증, 20%를 테스트에 사용.
- 98.0% 정확도를 기록하며 기존 연구보다 높은 성능을 보임.
C. Model Visualization



- 감정별로 모델이 중요하게 여기는 얼굴 영역을 분석하기 위해 시각화 기법을 적용함.
- NxN 크기의 영역을 하나씩 가리면서(prediction occlusion) 모델이 감정을 잘못 예측하는 경우 해당 영역이 중요한 부분으로 간주됨.
- 행복(Happiness) → 입 주변이 중요, 분노(Anger) → 눈썹 및 눈 주변이 중요.
- 중립(Neutral) → 얼굴 전체가 중요한 특징을 포함.
5. Conclusion
Novelty & Contribution
최종 요약
| AspectKey | Takeaways |
| Novelty | ① 감정별 중요한 얼굴 부위에 집중하는 주의 기반 CNN 모델 설계 ② 단순한 구조(10개 이하의 CNN 계층)로도 높은 성능 달성 ③ 다양한 데이터셋(FER2013, CK+, JAFFE, FERG)에서 검증 ④ 시각화 기법(Feature Occlusion)을 이용한 모델 해석 가능성 향상 |
| Contribution | ① 주의 기반 CNN을 활용한 감정 인식의 성능 향상 ② 최첨단 모델보다 높은 성능 (FER2013: 70.02%, CK+: 98.0%) ③ 다양한 데이터셋에서 일관된 성능 유지 ④ 감정별 중요한 얼굴 영역을 분석하여 모델 해석 가능성 증가 ⑤ 경량화된 구조로 감정 인식 실시간 적용 가능성 증대 |
즉, 본 연구는 감정 인식 모델의 성능을 향상시킬 뿐만 아니라, 모델이 감정을 인식하는 과정에 대한 해석 가능성을 높이고, 기존보다 가벼운 구조로도 높은 성능을 달성하는 데 기여함.