논문 링크: 1612.06321
깃허브 링크: https://github.com/tensorflow/models/tree/master/research/delf
models/research/delf at master · tensorflow/models
Models and examples built with TensorFlow. Contribute to tensorflow/models development by creating an account on GitHub.
github.com
Abstract
본 논문은 대규모 이미지 검색을 위한 attentive local feature descriptor인 DELF (DEep Local Feature)를 제안한다. 이 특징은 이미지 수준의 annotation만을 사용하여 landmark 이미지 데이터셋에서 학습된 CNN 기반으로 만들어진다.
이미지 검색을 위한 semantic local feature를 식별하기 위해, 우리는 keypoint selection을 위한 attention 메커니즘을 함께 제안한다. 이 메커니즘은 descriptor와 대부분의 네트워크 계층을 공유한다.
이 프레임워크는 기존 keypoint detector 및 descriptor의 대체로 활용될 수 있어, 더 정확한 feature matching과 geometric verification을 가능하게 한다. 또한, 신뢰도 점수를 산출하여 false positive를 효과적으로 제거할 수 있으며, 특히 정답이 없는 쿼리에 대해 강건하다.
제안된 descriptor의 성능 평가를 위해 Google-Landmarks dataset이라는 새로운 대규모 데이터셋을 소개한다. 이 데이터셋은 배경 잡음, 부분 occlusion, 다수 landmark, 다양한 스케일 등 여러 도전 과제를 포함한다. 실험 결과, DELF는 기존 state-of-the-art global 및 local descriptor보다 현저히 우수한 성능을 보인다.
1. Introduction
대규모 이미지 검색은 object detection, visual place recognition, product recognition과 같은 실용적인 컴퓨터 비전 응용과 직결되는 핵심 과제이다. 기존에는 handcrafted feature 및 indexing 방식에서 시작하여, 최근에는 CNN 기반 global descriptor 학습으로 발전해왔다.
하지만, CNN 기반 global descriptor는 clutter, occlusion, viewpoint, illumination 변화가 많은 대규모 데이터셋에서는 성능이 저하될 수 있다. 이들은 patch-level matching을 제공하지 못하므로, 배경 잡음이나 부분 가림이 있는 경우 부분적인 이미지 매칭이 어렵다는 단점이 있다.
최근에는 CNN 기반 local feature가 patch-level matching을 위해 제안되었지만, 이들은 의미 있는 semantic feature를 선택하지 못하고, 이미지 검색에는 최적화되어 있지 않다.
기존의 이미지 검색 연구는 대부분 적은 수의 쿼리와 제한된 landmark만 포함된 소규모~중간 규모 데이터셋에서 이루어졌다 (예: Oxford5k, Paris6k, Holidays). 이는 알고리즘의 일반화 가능성과 통계적 의미를 갖춘 성능 평가를 어렵게 만든다.
이 논문의 주요 목표는 다음과 같다:
- CNN 기반의 새로운 local feature descriptor를 개발하여 대규모 이미지 검색을 수행함.
- 이를 위해, 13K개 landmark에서 100만 장 이상의 이미지로 구성된 Google-Landmarks 대규모 데이터셋을 새롭게 구축함. 추가로 다양한 특성을 가진 10만 개의 쿼리 이미지도 포함되며, 이 중 일부는 정답 이미지가 존재하지 않는 distractor이다.
- 이미지 수준 레이블만을 이용한 weakly-supervised 학습 방식으로 attention 기반의 CNN local feature (DELF)를 제안함.
- attention model은 기존 CNN 구조를 재사용하며, 추가 연산 없이 relevance score를 산출함. 이는 단 한 번의 forward pass로 local descriptor와 keypoint를 동시에 추출할 수 있게 한다.
- 제안된 DELF 기반 이미지 검색 시스템은 기존의 global 및 local descriptor보다 유의미하게 높은 성능을 달성함.
2. Related Work
이미지 검색 분야에서는 평가를 위한 표준 데이터셋이 존재하며, 그 예시는 다음과 같다:
- Oxford5
5,062장의 Oxford 건물 이미지와 55개의 쿼리 이미지로 구성됨. - Paris6k
Paris의 6,412개 랜드마크 이미지와 55개의 쿼리 이미지로 구성됨. - Holidays dataset
1,491장 (그 중 500장이 쿼리)으로 구성되며, 개인 휴가 사진을 포함함. - 이 데이터셋들은 모두 규모가 작고, 쿼리 수가 적으며 랜드마크 다양성도 제한적임.
- Pitts250k는 더 큰 규모지만, 패턴 반복이 많은 장소에 특화되어 있어 일반적인 이미지 검색에는 부적합함.
기존 이미지 검색 방식
1. 핸드크래프트된 Local Feature 기반 방식
- SIFT, SURF, Gabor 기반 CONGAS 등
- KD-tree, Vocabulary tree 기반의 近접 이웃 검색을 활용
- Geometric re-ranking과 함께 쓰이면 높은 정확도를 달성할 수 있음
2. Local Feature의 Aggregation
- VLAD , Fisher Vector (FV) 방식
- 많은 local descriptor들을 하나의 compact한 global vector로 합침
- 인덱스 크기를 작게 유지하면서도 성능이 우수
3. CNN 기반 Global Descriptor
- Pretrained 또는 fine-tuned CNN을 사용
- Triplet loss 기반 학습 → 관련 이미지 간의 ranking을 유지함
- NetVLAD, siaMAC 등은 deep local features를 VLAD, FV 등 기존 aggregation 기법에 결합하기도 함
- 일부 연구는 local feature aggregation 방식 자체를 새롭게 제안함
4. CNN 기반 Local Feature
- Verdie et al.: keypoint detector 학습
- Yi et al.: feature orientation 예측
- MatchNet, DeepCompare: patch 표현과 metric을 함께 학습
- LIFT: keypoint detection, orientation estimation, description을 end-to-end로 학습
→ 하지만 이들 방식은 semantic feature selection을 고려하지 않아 image retrieval에 특화되지 않음
5. Attention Mechanism 기반 시각 인식
- Object Detection, Semantic Segmentation, Image Captioning, VQA 등에 사용됨
- 그러나 image retrieval을 위한 feature 학습에 attention 적용은 드물다
즉,
- 기존 방법들은 대부분 global descriptor 또는 handcrafted local feature에 의존
- 일부 CNN 기반 local feature 기법은 등장했지만, 의미 있는 feature 선택이 어렵고 retrieval 정확도는 낮음
- DELF는 이를 극복하고자, CNN 기반의 local feature와 attention 기반 keypoint selection을 통합한 새로운 프레임워크임
3. Google-Landmarks Dataset
데이터셋 구축 방식
- 본 데이터셋은 [44]의 알고리즘을 기반으로 구축됨.
- 기존 이미지 검색용 데이터셋 (Oxford5k, Paris6k, Holidays)과 비교했을 때:
- 훨씬 큰 규모 (약 106만 장의 이미지)
- 12,894개의 고유한 랜드마크
- 111,036개의 쿼리 이미지 포함
- 지리적으로 다양함: 187개국, 4,872개 도시
- 이미지들은 GPS 좌표와 함께 제공됨.
특징 및 도전 과제
- 기존 데이터셋들은 대부분 landmark-centric, 즉 landmark가 뚜렷하게 중심에 있음 → global descriptor 성능이 잘 나옴.
- 반면 Google-Landmarks는 현실적인 이미지로 구성되어 있음:
- 전경/배경 잡음(clutter), 가림(occlusion), 부분적으로 잘린 객체, 다수의 landmark
- 일부 쿼리 이미지에는 랜드마크가 존재하지 않음 → 정답이 없는 distractor 쿼리 존재
※ Distractor 쿼리: 데이터베이스에 정답이 없는 쿼리로, 알고리즘의 잡음/무관한 입력에 대한 강건성 평가에 활용됨


Ground-truth 구축 방법
- 이미지의 visual feature와 GPS 좌표를 활용하여 clustering 수행
- 각 클러스터에 landmark ID를 부여
- 쿼리 이미지의 GPS 위치와 클러스터 중심 간의 거리가 25km 이하이면 같은 랜드마크로 간주
※ 이 방식은 일부 GPS 오차, 멀리서 찍은 landmark 이미지 등의 문제로 인해 noise를 포함할 수 있음
→ 하지만 수작업 검증 결과 정확도가 높고, retrieval 평가에는 큰 문제가 없음
이 데이터셋의 의의
- 기존보다 훨씬 도전적인 조건을 포함함 (예: occlusion, clutter, 다양한 뷰포인트)
- 특히, 정답이 없는 쿼리 포함 → retrieval 시스템의 현실적 성능 평가 가능
- 알고리즘의 일반화 성능 및 robustness 평가에 매우 유리한 테스트셋
4. Image Retrieval with DELF
DELF 기반의 이미지 검색 시스템은 다음과 같은 4단계 파이프라인으로 구성됨:
- Dense Local Feature Extraction
- Attention-based Keypoint Selection
- Dimensionality Reduction
- Indexing & Retrieval
4.1 Dense Localized Feature Extraction
- Fully Convolutional Network (FCN)을 사용하여 이미지에서 dense하게 local feature를 추출함.
- 기반 네트워크: ResNet-50의 conv4_x 블록 출력
- 다양한 스케일 처리를 위해 image pyramid를 사용함
- 각 feature는 receptive field 중심 좌표에 매핑되며, 다양한 크기의 영역을 표현함
→ 예: 원본 스케일에서는 291×291 픽셀의 영역을 하나의 feature로 표현 - 학습 방식:
- ImageNet으로 사전 학습된 ResNet-50을 기반 모델로 사용
- Landmark image dataset을 사용해 cross-entropy loss로 fine-tuning 진행
- 입력 이미지는 중앙을 잘라 250×250으로 리사이즈한 후, 224×224 random crop 사용하여 학습

(a) : Descriptor Fine-tuning 구조
학습된 local feature는 랜드마크 검색에 더 특화된 표현을 학습함
객체나 패치 수준의 라벨 없이도, 이미지 수준 라벨만으로도 학습이 가능함
4.2 Attention-based Keypoint Selection
왜 필요한가?
- Dense feature 중 대부분은 쓸모없는 정보이므로, 정확도와 효율성을 위해 중요한 keypoint만 선택해야 함.
4.2.1 Learning with Weak Supervision
- attention module은 각 feature에 대해 relevance score를 산출함.
- 각 feature $f_n \in \mathbb{R}^d$, $n = 1, ..., N$에 대해 score function $\alpha(f_n; \theta)$을 학습
전체 이미지 임베딩은 다음 수식으로 표현됨:
$$y = W \left( \sum_n \alpha(f_n; \theta) \cdot f_n \right) \tag{1}$$
- $W \in \mathbb{R}^{M \times d}$: landmark 분류를 위한 마지막 fully-connected layer의 가중치
- $\alpha(f_n; \theta)$: feature $f_n$에 대한 attention score
Loss function (cross-entropy):
$$\mathcal{L} = -y^* \cdot \log \left( \frac{\exp(y)}{\mathbf{1}^T \exp(y)} \right) \tag{2}$$
- $y^*$: ground-truth one-hot label vector
- $\mathbf{1}$: 전부 1인 벡터
attention score에 대한 gradient 계산:
$$\frac{\partial \mathcal{L}}{\partial \theta} = \frac{\partial \mathcal{L}}{\partial y} \sum_n W f_n \frac{\partial \alpha_n}{\partial \theta} \tag{3}$$
Attention Network 구조
- score 함수 $\alpha(\cdot)$는 non-negative 값을 출력해야 하므로, softplus 활성함수 사용
- 간단한 1×1 convolutional filter 두 층으로 구성된 2-layer CNN

(b) : Attention-based Training 구조 → yellow 영역이 attention module
4.2.2 Training Attention
- 실제 학습은 두 단계로 진행됨:
- descriptor 학습: fine-tuning된 ResNet으로 local descriptor 학습
- attention 학습: descriptor를 고정하고 attention 네트워크만 학습
- 랜덤 이미지 스케일 조정을 통해 attention이 다양한 크기의 feature에 잘 대응할 수 있도록 학습
- 이미지 → center crop 후 900×900으로 리사이즈
- 720×720 crop 후, 임의로 크기 조절 ($\gamma \leq 1$)하여 입력
4.2.3 특징 (Conventional vs. Proposed)
- 기존 방식(SIFT, LIFT 등)은 keypoint → descriptor 순서
- DELF는 descriptor → attention → keypoint 순서
→ 높은 수준의 의미 정보를 담고 있는 feature에서 가장 중요한 것만 선택
따라서 DELF는 재현성(repeatability) 뿐 아니라 구분성(discriminativeness)도 함께 고려함
4.3 Dimensionality Reduction
- 선택된 feature는:
- L2 정규화
- PCA를 통해 40차원으로 축소 (compact + discriminative)
- 다시 L2 정규화
→ 8GB 메모리로 10억 개의 descriptor 저장 가능
4.4 Image Retrieval System
- 쿼리/데이터베이스 이미지로부터 local descriptor 추출
- 각 이미지당 attention score가 가장 높은 feature 1000개를 선택
- 각 feature는 40차원, L2 정규화됨
Indexing
- KD-tree + Product Quantization (PQ) 사용
- 각 40D descriptor는 10개의 sub-vector로 나뉘고, 각 sub-vector는 25개 centroid로 50-bit PQ 인코딩
- Inverted Index 구성:
- 코드북 크기: 8K
- 각 Voronoi 셀은 KD-tree로 분할됨
- 각 하위 노드는 Locally Optimized PQ사용 (30K feature 이하)
Querying
- 쿼리 이미지의 각 feature에 대해:
- nearest neighbor 검색 (asymmetric distance 사용 → query는 PQ로 압축하지 않음)
- top-K 매칭 결과를 각 데이터베이스 이미지 단위로 집계
- RANSAC을 통해 기하학적 정합성 확인
- inlier 수를 score로 사용하여 이미지 순위 결정
→ Distractor 쿼리는 이 단계에서 자연스럽게 걸러짐
Metrics
- 메모리: 전체 10억 descriptor를 8GB 이내로 저장 가능
- 검색 속도: 1 CPU 기준 2초 미만
- 쿼리당 soft-assign된 centroid 수: 5
- inverted index 내 최대 탐색 노드 수: 10K

- 왼쪽: DELF feature 추출 및 attention 기반 keypoint 선택 과정
- 오른쪽: DELF feature 기반 이미지 검색 시스템 흐름
5. Experiments
이 장에서는 제안된 DELF가 기존 global/local feature descriptor들과 비교해 얼마나 효과적인지 실험적으로 검증하며, 실험은 다음과 같은 측면에서 수행됨:
- 대규모 Google-Landmarks 데이터셋에서의 비교
- 기존 이미지 검색 데이터셋에서의 성능
- fine-tuning 및 attention의 효과 분석
- 질적(qualitative) 결과 시각화
5.1 Implementation Details
Multi-scale Descriptor Extraction
- 이미지 피라미드 스케일은 0.250.25 ~ 2.02.0, 총 7단계
- 스케일 간 간격은 2\sqrt{2} 배수
- 스케일이 커질수록 receptive field 크기는 작아짐
예: 스케일 2.0에서는 receptive field 크기 = 146×146
Training Dataset
- Landmark 데이터셋 사용:
- LF (Landmarks-full): 586개 랜드마크, 140,372장 이미지
- LC (Landmarks-clean): SIFT 기반 매칭 후 필터링된 35,382장 이미지
- LC: descriptor fine-tuning에 사용
- LF: attention 학습에 사용
Parameters
- 쿼리당 최대 1000개 feature 추출
- 각 쿼리 feature에 대해 top-K = 60 nearest neighbor 탐색
- 각 feature는 40차원
5.2 Compared Algorithms
- DIR (Deep Image Retrieval)
- state-of-the-art global descriptor (ResNet101 기반, 2048D)
- Query Expansion (QE) 버전도 평가함
- siaMAC
- VGG16 기반 global descriptor (512D)
- QE 포함 버전도 평가
- CONGAS
- Gabor wavelet 기반 handcrafted local descriptor (40D)
- LIFT
- keypoint detection, orientation, description을 joint하게 학습하는 deep local descriptor (128D)
5.3 Evaluation Metric
기존 mAP는 distractor에 취약
→ 본 논문에서는 절대 점수를 기반으로 한 Precision-Recall 평가 방식을 도입
- Precision:
$$\text{PRE} = \frac{\sum_q |R_q^{\text{TP}}|}{\sum_q |R_q|}$$
- Recall:
$$\text{REC} = \sum_q |R_q^{\text{TP}}|$$
- $R_q$: query $q$에 대해 검색된 이미지 집합
- $R_q^{\text{TP}} \subseteq R_q$: 정답(positive)으로 판별된 이미지들
※ mAP 대신 전체 query를 합친 micro-level PR curve로 표현
5.4 Quantitative Results

- DELF+FT+ATT가 모든 baseline보다 성능이 뛰어남
- DELF-noFT: 사전 학습만 된 feature
- DELF+FT: fine-tuning만 수행
- DELF-noFT+ATT: 사전 학습된 feature에 attention만 추가
→ attention이 성능 향상에 더 큰 기여
→ global descriptor (DIR)는 distractor에 취약, 특히 query expansion 사용 시 성능 하락
Memory Usage
| 방법 | 메모리 |
| DELF | 8GB |
| CONGAS | 8GB |
| DIR (2048D) | 약 8GB |
5.5 Qualitative Results
DELF vs DIR

- DELF는 cluttered 배경에서도 정확한 local matching 수행
- DIR은 비슷한 scene을 찾지만 정확한 인스턴스를 구별하지 못함

- 식별력이 떨어지는 지역에서의 오탐 (ex. 바닥무늬, 식물 등)이 DELF에겐 문제로 작용할 수 있음
DELF vs CONGAS

- CONGAS는 정확도 부족
- DELF는 occlusion, clutter, out-of-view landmark 조건에서도 robust하게 작동
- Red line: matching된 receptive field 중심 연결선
Keypoint Selection Comparison

| 항목 | 설명 |
| (a) | 입력 이미지 |
| (b) | DELF-noFT (pretrained CNN의 L2 norm) |
| (c) | DELF+FT (fine-tuned CNN의 L2 norm) |
| (d) | DELF+FT+ATT (주의 기반 score) → clutter 제거 효과 탁월 |
- 실험 대상:
- Oxford5k, Oxford105k
- Paris6k, Paris106k
- DELF + DIR (late fusion) 방식 사용 → DELF의 보완적 역할 확인
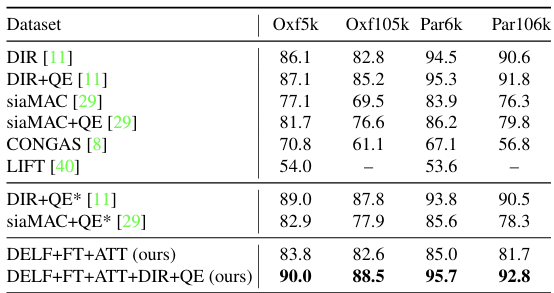
→ DELF 단독 성능도 좋지만, global descriptor와 결합 시 추가 향상
6. Conclusion
본 논문에서는 DELF (DEep Local Feature)라는 새로운 local feature descriptor를 제안함. 이 방법은 대규모 이미지 검색에 특화되어 있으며, 다음과 같은 핵심 기여를 포함함:
- Weak supervision 기반 학습
- 이미지 수준의 레이블만으로 학습 가능
- 객체나 patch 수준의 annotation 없이도 의미 있는 local descriptor를 학습함
- Attention 기반 키포인트 선택
- CNN 구조와 결합된 효율적인 attention 모듈을 통해
- 하나의 forward pass로 descriptor와 keypoint를 동시에 추출 가능
- 대규모 평가를 위한 데이터셋 구축
- Google-Landmarks dataset을 새롭게 제안
- 100만 장 이상의 landmark 이미지와 10만 장의 쿼리 이미지, 13,000개 landmark 클래스
- clutter, occlusion, viewpoint 등 현실적인 조건 포함
- 탁월한 실험 결과
- 기존 global/local descriptor보다 현저히 우수한 성능을 보여줌
- 기존 Oxford/Paris 등의 데이터셋에서도 성능 향상에 기여함
- 특히, global descriptor와의 late fusion 시 상호 보완적 역할을 수행함
DELF는 정확도와 확장성, 학습 효율성을 모두 고려한 구조로,
향후 대규모 이미지 검색 시스템의 핵심 컴포넌트로 활용 가능함을 실험적으로 입증함.