앙상블(Ensemble) 개념 정리
- 앙상블(Ensemble): 여러 개의 모델을 결합해 더욱 높은 예측 성능을 얻는 기법임.
- Voting: 서로 다른 알고리즘(결정 트리, 로지스틱 회귀, KNN 등)을 조합해, 투표 형태로 최종 예측을 결정함.
- 하드 보팅: 각각 분류기의 최종 결괏값 중 가장 많이 나온 클래스를 선택(다수결)
- 소프트 보팅: 각각 분류기가 예측한 확률을 모두 합산, 평균 낸 뒤 가장 확률 높은 클래스를 선택
- Bagging: 하나의 알고리즘을 여러 번 학습하되, 중복을 허용하는 샘플링(bootstrap)으로 각 모델을 만듦.
- RandomForest: Decision Tree를 Bagging 방식으로 여러 개 결합한 모델임. 성능이 우수하고 사용이 쉬움.
- Boosting: 약한 학습기를 순차적으로 학습하면서 이전 학습에서의 오차를 보완해 나가는 방식임. 오차를 점진적으로 줄여가는 것이 특징.
- AdaBoost
- GradientBoost
- XGBoost: 병렬화 등 성능 최적화로 GBM 대비 속도가 빠르고 예측력이 높음
- LightGBM: 더 빠른 학습 속도와 높은 예측 성능을 제공함
- 부스팅의 장단점:
- 장점: 높은 예측 성능, Kaggle 등에서 자주 쓰임
- 단점: 학습 시간 증가, 이상치에 민감할 수 있음
코드 리뷰
- 데이터 로드 및 전처리
- df = data.dropna()로 결측치를 제거해 학습에 적합한 데이터로 만듦.
- train_test_split을 통해 학습용/테스트용 데이터를 분할함.
- 성능 평가 함수
- mse_eval(name_, pred, actual):
- 예측값(pred)과 실제값(actual)의 MSE(Mean Squared Error) 계산.
- 결과를 막대그래프로 시각화하여 여러 모델 성능을 직관적으로 비교할 수 있게 함.
- plot_predictions(name_, pred, actual):
- 예측값과 실제값의 스캐터 플롯을 통해 시각적으로 성능 확인 가능함.
- mse_eval(name_, pred, actual):
- 기본 회귀 모델 학습
- LinearRegression, Ridge, Lasso, ElasticNet 등을 간단히 적용해 봄.
- 규제 항(Regularization) α값에 따라 과적합을 완화하거나 성능 조정 가능함.
linear_reg = LinearRegression(n_jobs=-1)
linear_reg.fit(x_train, y_train)
y_pred = linear_reg.predict(x_test)
mse_eval('LinearRegression', y_pred, y_test)

- 파이프라인(Pipeline)과 폴리노미얼(PolynomialFeatures)
- 전처리(Scaling) + 모델을 연결해 코드 가독성과 유지보수성을 높임.
- 다항식 특징(PolynomialFeatures)으로 비선형 관계도 학습 가능함.
elasticnet_pipeline = make_pipeline(
StandardScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
poly_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False),
StandardScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)

- VotingRegressor
- 여러 서로 다른 모델(예: LinearRegression, Ridge, Lasso, ElasticNet 등)의 예측값을 평균해 최종 예측을 수행함.
- 분류 문제에서는 VotingClassifier를 사용하며, voting='hard' or voting='soft' 방식 선택 가능함.
- VotingClassifier(estimators=[...], voting='hard/soft') 13-1. Voting 실습
- estimators는 리스트 안에 튜플 형태로 모델을 정의해야 함.
- voting='soft' → 확률을 평균해 예측, voting='hard' → 다수결.
- 보팅 방식으로 묶어 사용했을 때, 개별 모델 대비 정확도가 높아지는 경우가 많음.
- 유의: 항상 보팅이 단일 모델보다 무조건 좋은 것은 아니며, 데이터 특성과 모델 선택에 따라 결과가 달라질 수 있음.
- LogisticRegression 정확도: 0.9210
- KNeighborsClassifier 정확도: 0.9122
- VotingClassifier 정확도: 0.9386
⇒ 결론: 예시에서는 보팅이 개별 모델보다 정확도가 더 높았음.
single_models = [
('linear_reg', linear_reg),
('ridge', ridge),
('lasso', lasso),
...
]
voting_regressor = VotingRegressor(single_models, n_jobs=-1)
voting_regressor.fit(x_train, y_train)
voting_pred = voting_regressor.predict(x_test)
mse_eval('VotingRegressor', voting_pred, y_test)


▼ 13-1. Voting 실습
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 1) 유방암 데이터 로드
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
# 2) 분류기(모델) 정의
lr_clf = LogisticRegression(solver='liblinear')
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 3) 보팅 분류기 생성
vo_clf = VotingClassifier(
estimators=[('LR', lr_clf), ('KNN', knn_clf)],
voting='soft' # soft 보팅
)
# 4) 학습/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
cancer.data,
cancer.target,
test_size=0.2,
random_state=42
)
# 5) 분류기별 학습 & 예측 정확도 비교
classifiers = [lr_clf, knn_clf, vo_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
name = classifier.__class__.__name__
print(f'{name} 정확도: {accuracy_score(y_test, pred)}')- Bagging & RandomForest

- Bagging: 같은 알고리즘을 다른 샘플링 조합으로 학습시켜 예측값을 결합함.
- RandomForest: Decision Tree 기반의 Bagging 앙상블이며, 성능과 사용성이 뛰어남.
- n_estimators, max_depth 등 하이퍼파라미터를 조정해 성능 개선 시도 가능함.
rfr = RandomForestRegressor(random_state=42)
rfr.fit(x_train, y_train)
rfr_pred = rfr.predict(x_test)
mse_eval('RandomForestRegressor', rfr_pred, y_test)- GradientBoosting
- 부스팅 알고리즘 중 하나로, 약한 학습기를 순차적으로 학습하면서 이전 단계의 오차를 보완함.
- 장점: 높은 예측 성능.
- 단점: 학습 시간 긴 편.
gbr = GradientBoostingRegressor(random_state=42)
gbr.fit(x_train, y_train)
gbr_pred = gbr.predict(x_test)
mse_eval('GradientBoostingRegressor', gbr_pred, y_test)- XGBoost
- GBM을 병렬화 최적화한 구현체로, 속도와 성능이 개선됨.
▼ 13-2 XGBoost 실습
더보기
XGBoost 란?
- Extreme Gradient Boosting의 약자.
- Gradient Boost를 병렬 학습 등이 가능하도록 고성능, 고효율로 구현한 라이브러리.
- Regression, Classification 문제 모두 지원.
- 높은 예측 성능, 빠른 학습 속도, 자원 효율 때문에 인기가 많음.
XGBoost의 장점
- GBM 대비 빠른 속도: 내부적으로 병렬 처리(Parallelization)와 다양한 최적화가 적용됨.
- 과적합 규제(Regularization):
- L1, L2 규제 파라미터(λ,α)를 제공하여 오버피팅을 효과적으로 방지함.
- 여러 가지 평가 지표 및 커스텀 옵션 지원:
- 다양한 objective(목적 함수)와 eval_metric(평가 함수)을 사용할 수 있음.
- Early Stopping 기능 제공:
- 일정 횟수(epoch) 동안 점수가 개선되지 않으면 학습을 자동으로 중단해 시간 절약.
- 트리 기반 앙상블 사용:
- Decision Tree의 앙상블로 분류/회귀 모두 예측 성능이 우수함.
주요 하이퍼파라미터
- booster: 트리를 사용할지(gbtree), 선형 모델을 사용할지(gblinear), dart 등을 선택.
- learning_rate(eta):
- 기본값: 0.3
- 클수록 학습 빠르지만 과적합 위험, 작을수록 학습 느리지만 일반화 성능이 좋아질 수 있음.
- n_estimators:
- 생성할 약한 학습기(트리) 수, 기본값: 100
- learning_rate가 작을수록 큰 값 필요.
- max_depth:
- 트리의 최대 깊이. 기본값: 6
- 클수록 복잡도가 높아져 과적합 가능성 ↑.
- min_child_weight:
- 자식 노드를 split할 최소 가중치 합, 기본값: 1
- 값이 클수록 과적합 억제.
- gamma:
- 리프 노드 추가 분할 최소 손실 감소값, 기본값: 0
- 값이 높을수록 분할 적게 일어나 과적합 억제.
- subsample:
- 각 트리 학습에 사용할 데이터 샘플링 비율, 기본값: 1
- 0.5~1 사이로 조절, 낮출수록 과적합 억제.
- colsample_bytree:
- 각 트리마다 사용될 피처의 샘플링 비율, 기본값: 1
- 0.5~1 사이로 조절, 낮출수록 과적합 억제.
- reg_alpha(alpha), reg_lambda(lambda):
- L1, L2 규제 파라미터로 오버피팅 방지에 효과적.
- objective:
- 예) reg:squarederror, binary:logistic, multi:softmax, multi:softprob 등.
- eval_metric:
- 예) rmse, mae, logloss, auc, error, merror 등.
- seed:
- 재현성 유지를 위한 난수 고정.
과적합 방지용 파라미터 조정 요령
- learning_rate 낮추기 (대신 n_estimators는 높이기)
- max_depth 낮추기
- min_child_weight 높이기
- gamma 높이기
- subsample, colsample_bytree 낮추기
- reg_alpha, reg_lambda(규제 항) 적극 사용
사용 예시
1. XGBClassifier 예시
import xgboost as xgb
import matplotlib.pyplot as plt
# 모델 선언
model = xgb.XGBClassifier()
# 모델 학습
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)2. XGBRegressor 예시
import xgboost as xgb
# 모델 선언
my_model = xgb.XGBRegressor(learning_rate=0.1, max_depth=5, n_estimators=100)
# 모델 학습
my_model.fit(X_train, y_train, verbose=False)
# 예측
y_pred = my_model.predict(X_test)시각화
- graphviz 라이브러리 설치 후, 결정트리 구조나 피처 중요도를 시각화 가능.
- xgb.plot_importance(my_model)
- 피처 중요도(Feature Importance)를 bar 형태로 확인.
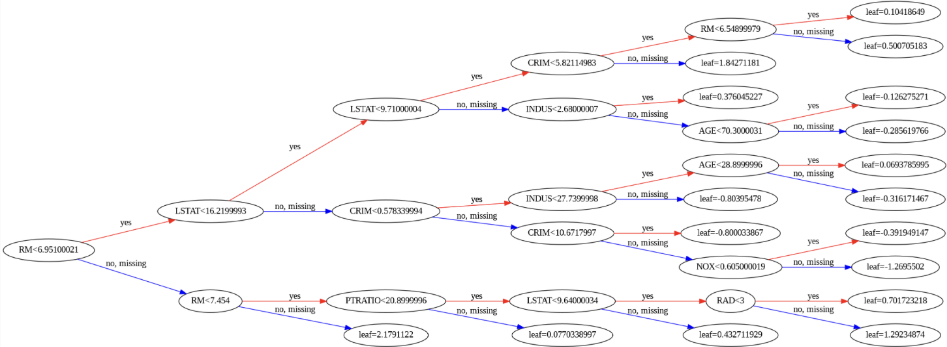
- xgb.plot_tree(my_model, num_trees=0, rankdir='LR')
- 특정 트리의 구조를 시각화.
- plt.gcf().set_size_inches(150, 100) 같은 방식으로 이미지 크기 조절.
# 예시
xgb.plot_importance(my_model)
xgb.plot_tree(my_model, num_trees=0, rankdir='LR')
fig = plt.gcf()
fig.set_size_inches(150, 100)
plt.show()- 트리 구조를 자세히 살펴보며 가지치기 방식이나 분할 기준 등을 직관적으로 파악할 수 있음.
- XGBoost 특성상 규제와 분할 방식이 적용되어, 트리 시각화가 일반 Decision Tree와 약간 다를 수 있음.
정리
- XGBoost는 GBM의 성능을 한층 더 올린 강력한 라이브러리로, 빠른 학습 속도와 높은 예측 성능, 다양한 규제 옵션 등을 제공함.
- 하이퍼파라미터를 적절히 조정하면 과적합을 억제하고 좋은 성능을 낼 수 있음.
- 내부 트리 구조와 피처 중요도 등을 쉽게 시각화할 수 있어, 모델 해석에도 유리함.
xgb = XGBRegressor(random_state=42)
xgb.fit(x_train, y_train)
xgb_pred = xgb.predict(x_test)
mse_eval('XGBoost', xgb_pred, y_test)- LightGBM
- XGBoost보다 학습 속도가 더 빠른 기법으로, 성능 또한 높음.
lgbm = LGBMRegressor(random_state=42)
lgbm.fit(x_train, y_train)
lgbm_pred = lgbm.predict(x_test)
mse_eval('LGBM', lgbm_pred, y_test)

핵심 포인트
- Voting: 서로 다른 모델 조합 → 결과 평균 또는 다수결(분류 시)
- Bagging: 하나의 모델로 중복 샘플링(bootstrap) → 결과 합산
- RandomForest: Decision Tree 기반 Bagging 앙상블 → 간편 + 성능 우수
- Boosting: 순차 학습으로 오차 보완 → 성능 우수하나, 학습 시간 증가
- XGBoost / LightGBM: GBM을 최적화한 구현 → 더 빠르고 성능 향상
모델 선택 시, 데이터 크기, 학습 시간, 성능 지표, 하이퍼파라미터 튜닝 비용 등을 종합적으로 고려해야 함.
Tuning(예: learning_rate, n_estimators, max_depth)을 적절히 수행하면 예측 성능이 크게 향상될 수 있음.